前言
人工智能、机器学习和深度学习正在越来越多的行业发挥着重要的作用。领域大牛吴恩达最近又有了小动作——正在完成一本开源的关于机器学习策略的手册,为各路道友提供构建机器学习项目的指导。根据 NG 的介绍,本书重点不是 ML 的算法,而是如何使 ML 算法发挥作用。琳琅满目的 ML 算法就像是工具箱里边的各种工具一样,这本书则是教会人们如何使用这些工具。笔者将对 NG 的这本
葵花宝典武林秘籍进行翻译,本篇博客是「第一章:绪论」,欢迎提出建议。
👉官网传送门
👉GitHub 项目传送门,欢迎 Star
1. 为什么需要机器学习策略?
机器学习是很多重要应用的基础,包括网页搜索、垃圾邮件分类、语音识别、商品推荐等等。假设你和你的团队正在开发一项机器学习相关的应用,并且想实现项目的快速迭代。本书介绍的内容将会为你提供帮助。
例子:创立一个关于猫咪图片的创业公司
假设你正在建立一个新的公司,该公司将为爱猫人士提供丰富的猫咪图片。

其中的一个潮流的方法就是:使用神经网络(Neural Network)搭建的计算机视觉系统(Computer Vision System)来检测图片中的猫。
但,很不幸的是,系统的学习算法准确率(Accuracy)并不尽如人意,因此,你在改进算法的过程中必须承担来自各个方面的巨大压力,那么,具体怎么办呢?
你的团队有很多改善算法点子,例如:
- 获取更多的数据:收集更多有关猫咪的图片;
- 收集更加多元化的训练集。比如,处在不同位置的猫咪的图片、有不同颜色的猫咪的图片、来自相机不同的参数拍摄出来的猫咪的图片……
- 通过跑更多轮数的梯度下降(Gradient Descent)迭代,延长网络的训练时间;
- 尝试更大规模的神经网络,比如设置更多的层数、隐藏单元、参数等;
- 尝试较小规模的神经网络;
- 尝试在网络加入正则化(Regularization)(例如 L2 正则化);
- 改变神经网络的结构(比如改变激活函数(Activation Function)、隐藏单元(Hidden Units)的数量等等)
- ……
如果选择了正确的优化方向,你将实现一个领先业界的猫咪图库平台,然后带领你的公司走向巅峰。但是如果你的优化措施选择并不好,大概率你会浪费掉数个月的时间,结果依旧没有改善。你将如何继续呢?
本书将会告诉你怎么做!大多数的机器学习问题都会留下一些线索,这些线索则会告诉你什么是有用的尝试,什么是徒劳的。学会理解这些暴露出来的线索能够节省你数月甚至上年的开发时间。
2. 如何利用本书帮助你的团队
读完本书之后,您将对如何为机器学习项目设定技术方向有一个深刻的理解。
但是你的队友们可能并不能理解您为什么要推荐一个这样一个特定的方向,比如,你建议要定义好一个单一的评价指标。关于你的建议,队友们并不信服,那么你将如何说服他们呢?
这也就是为什么本书的章节内容都这么简短的原因:你可以将需要的章节打印出来,让你的队友只需要阅读1-2页你想让他们理解的内容。
在优化问题上一个小小的改动就可能对你团队的产品产生巨大的影响。通过帮助团队做出高效的优化改动,来让你成为你团队里边的超级英雄吧。
3. 预备知识和符号约定
如果你在 MOOC 平台或者 Coursera 上学习过一些机器学习相关的课程,或者是你有一些应用「监督学习」的经验,你将能够理解本章节的内容。
我假设你对「监督学习」(Supervised Learning)非常熟悉:通过使用有标签的训练样例$(x,y)$,来学习一个从 $x$ 映射到 $y$ 的函数。「监督学习」算法包括了:线性回归(Linear Regression)、逻辑回归(Logistics Regression)和神经网络。机器学习有很多形式,但大部分有实用价值的机器学习算法主要来自「监督学习」。
我会经常提到「神经网络」(也叫做「深度学习」(Deep Learning)),你只需要对他们有一个基本的了解。
如果你对上边提及的概念还很不是熟悉的话,建议观看 Coursera 上机器学习前三周的课程,网址是:http://ml-class.org
4. 规模化驱动下的机器学习发展
很多深度学习相关的想法已经存在了数十年,为什么它们现在突然又火了起来?
近期的两个最大的驱动因素是:
- 海量可供使用的数据。人们在数字设备上所花费的时间大大提高,借此产生的海量数据,能够用于训练机器学习算法。
- 大规模的计算。从前几年开始,我们才敢设计足够大的网络来充分利用我们拥有的海量数据。
具体来说,如果使用那些传统的学习算法,比如逻辑回归,即使我们拥有再多的数据,算法的「学习曲线」会变得平坦(高原效应(Flattens Out))。这意味着,即使提供再多的数据,算法也会停止改进。
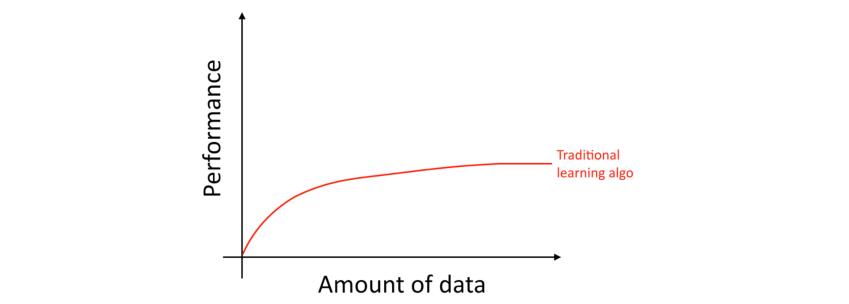
这看起来传统的算法并不知道怎么利用我们提供的海量数据。
对于同样的一个「监督学习」任务,如果你训练一个小型的神经网络,那么你可能会获得稍微好一点的性能表现。
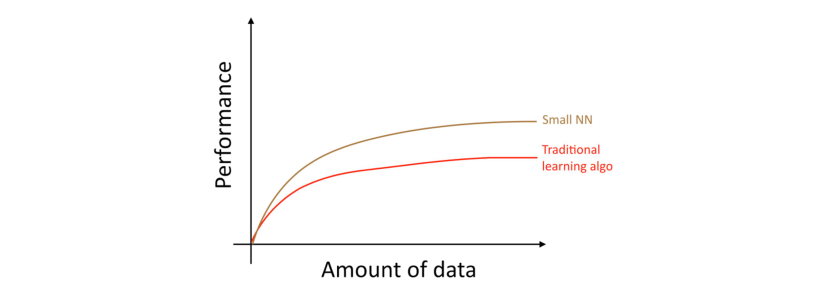
在这里,所谓的小型神经网络指的是该网络只有少数的隐藏单元/层/参数。最后,逐渐增大你网络的规模,网络的性能表现也会同步提高1。
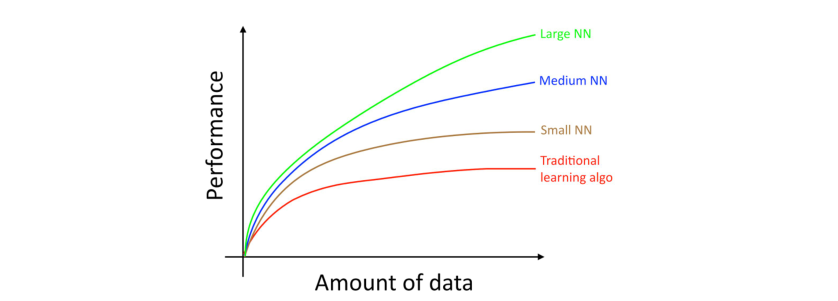
很多其他的细节,比如神经网络架构,也是非常重要的,这里边也有很多可以创新的地方。但,在今天来看,提高算法性能更有效的方法依然是:(i)规模更大的网络;(ii)更多的数据。
如何实现(i)和(ii)的过程非常复杂,本书将会详细讨论这些细节。我们将从对传统的学习算法和神经网络都有效的一般策略入手,为构建现代深度学习系统提出更加现代化的策略。
-
该图显示了神经网络在小数据集上也能做的很好,这个效果与神经网络在大型数据集上表现出的良好效果并不一致。在小型数据集中,更多的取决于如何对特征进行手工设计,传统算法可能表现的更好也可能表现更差。比如,你有 20 个训练样本,那么是否使用逻辑回归或者神经网络可能无关紧要,对特征的手工设计比选择何种学习算法会对性能表现产生更大的影响。但是如果你有 100 万的训练样本,使用神经网络将会是一个明智的选择。 ↩
本作品采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。欢迎转载,并请注明来自:黄钢的博客 ,同时保持文章内容的完整和以上声明信息!