GitHub项目传送门
欢迎Star
本篇博客有大量公式演示,不推荐使用手机查看
为什么选择序列模型?(Why Sequence Models?)
自然语言和音频都是前后相互关联的数据,对于这些序列数据需要使用 循环神经网络(Recurrent Neural Network,RNN) 来进行处理。
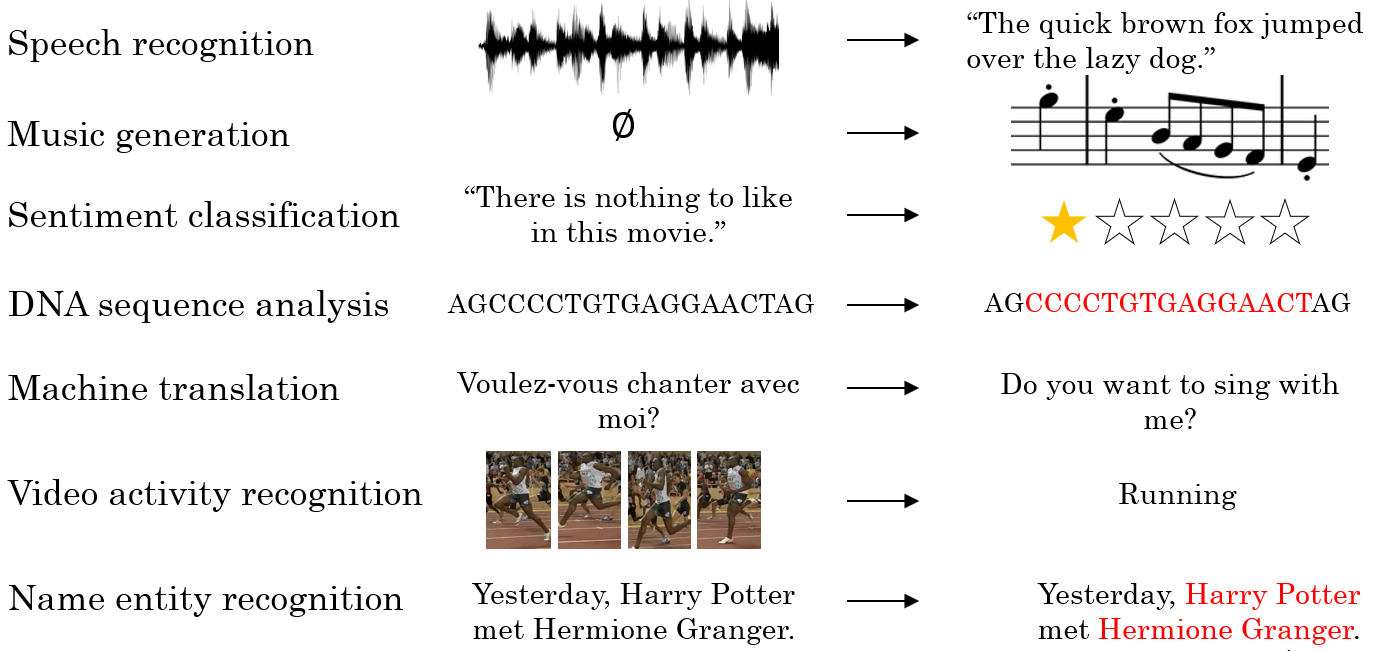
- 语音识别:将输入的语音信号$X$直接输出相应的语音文本信息$Y$。无论是语音信号还是文本信息均是序列数据。
- 音乐生成:生成音乐乐谱。只有输出的音乐乐谱$Y$是序列数据,输入$X$可以是空或者一个整数。
- 情感分类:将输入的评论句子$X$转换为相应的等级或评分。输入是一个序列,输出则是一个单独的类别。
- DNA序列分析:找到输入的DNA序列的蛋白质表达的子序列。
- 机器翻译:两种不同语言之间的想换转换。输入和输出均为序列数据。
- 视频行为识别:识别输入的视频帧序列中的人物行为。
- 命名实体识别:从输入的句子中识别实体的名字
所以这些问题都可以被称作使用标签数据$(X,Y)$作为训练集的监督学习。但从这一系列例子中可以看出序列问题有很多不同类型。有些问题里,输入数据$X$和输出数据$Y$都是序列,但就算在那种情况下,$X$,$Y$和有时也会不一样长。或者像上图编号1所示和上图编号2的$X$和$Y$有相同的数据长度。在另一些问题里,只有$X$或者只有$Y$是序列。
数学符号(Notation)
在对具体模型知识展开叙述之前,先对将要用到的数学符号进行定义。
- 输入 $x$ :如 “Harry Potter and Herminone Granger invented a new spell.”(以序列作为一个输入), $x^{⟨t⟩}$ 表示输入 $x$ 中的第 $t$个符号。
- 输出 $y$ :如“1 1 0 1 1 0 0 0 0”(人名定位),同样,用 $y^{⟨t⟩}$ 表示输出 $y$ 中的第 $t$ 个符号。
- $T_{x}$:用来表示输入 $x$ 的长度;
- $T_{y}$:用来表示输出 $y$ 的长度;
- $x^{(i)⟨t⟩}$:表示第 $i$ 个输入样本的第 $t$ 个符号,其余同理。
想要表示一个词语,需要先建立一个 词汇表(Vocabulary) ,或者叫 字典(ictionary) 。将需要表示的所有词语变为一个列向量,可以根据字母顺序排列,然后根据单词在向量中的位置,用 one-hot 向量(one-hot vector) 来表示该单词的标签:将每个单词编码成一个 $R^{\left | V \right | \times 1}$ 向量,其中 $\left | V \right |$ 是词汇表中单词的数量。一个单词在词汇表中的索引在该向量对应的元素为 1,其余元素均为 0。
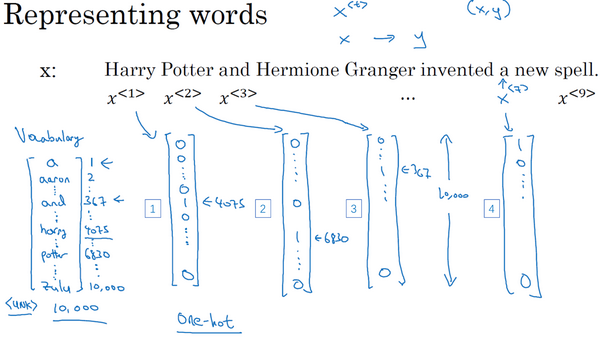
- 如上图:在这里$x^{⟨1⟩}$表示Harry这个单词,它就是一个第4075行是1,其余值都是0的向量(上图编号1所示);
- 同样的,$x^{⟨2⟩}$是个第6830行是1,其余位置都是0的向量(上图编号2所示);
- 以此类推。
- 那么还剩下最后一件事,如果遇到了一个不在词表中的单词,答案就是创建一个新的标记,也就是一个叫做Unknow Word的伪造单词,用$UNK$作为标记。
循环神经网络模型(Recurrent Neural Network Model)
假设句子:”Harry Potter and Herminone Granger invented a new spell.”。有9个输入单词。想象一下,把这9个输入单词,可能是9个one-hot向量,然后将它们输入到一个标准神经网络中,经过一些隐藏层,最终会输出9个值为0或1的项,它表明每个输入单词是否是人名的一部分。
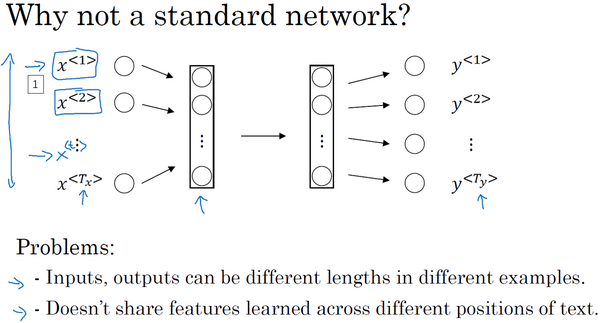
使用标准神经网络存在以下问题:
- 是输入和输出数据在不同例子中可以有不同的长度,不是所有的例子都有着同样输入长度$T_x$或是同样输出长度的$T_y$。即使每个句子都有最大长度,也许你能够填充(pad)或零填充(zero pad)使每个输入语句都达到最大长度,但仍然看起来不是一个好的表达方式。
- 一个像这样单纯的神经网络结构,它并不共享从文本的不同位置上学到的特征。具体来说,如果神经网络已经学习到了在位置1出现的Harry可能是人名的一部分,那么如果Harry出现在其他位置,比如$x^{⟨t⟩}$时,它也能够自动识别其为人名的一部分的话,这就很棒了。
- 之前我们提到过这些(上图编号1所示的$x^{⟨1⟩}$…$x^{⟨t⟩}$…$x^{⟨T_x⟩}$)都是10,000维的one-hot向量,因此这会是十分庞大的输入层。如果总的输入大小是最大单词数乘以10,000,那么第一层的权重矩阵就会有着巨量的参数。
为了解决这些问题,引入循环神经网络(Recurrent Neural Network,RNN)。一种循环神经网络的结构如下图所示:
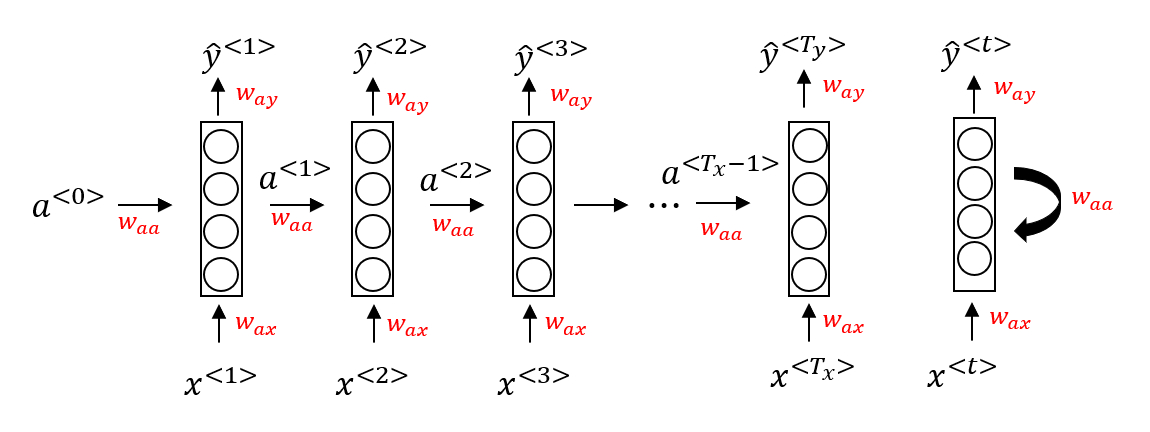
当元素 $x^{⟨t⟩}$ 输入对应时间步(Time Step)的隐藏层的同时,该隐藏层也会接收来自上一时间步的隐藏层的激活值 $a^{⟨t-1⟩}$,其中 $a^{⟨0⟩}$ 一般直接初始化为零向量。一个时间步输出一个对应的预测结果 $\hat y^{⟨t⟩}$。
- 在这个循环神经网络中,对应上边那个含有9个单词的句子,它的意思是在预测$\hat y^{⟨3⟩}$时,不仅要使用$x^{⟨3⟩}$的信息,还要使用来自$x^{⟨1⟩}$和$x^{⟨2⟩}$的信息来帮助预测$\hat y^{⟨3⟩}$。
- 但是这个循环神经网络的一个缺点就是它只使用了这个序列中之前的信息来做出预测,尤其当预测时,它没有用到$x^{⟨4⟩}$,$x^{⟨5⟩}$等等的信息。
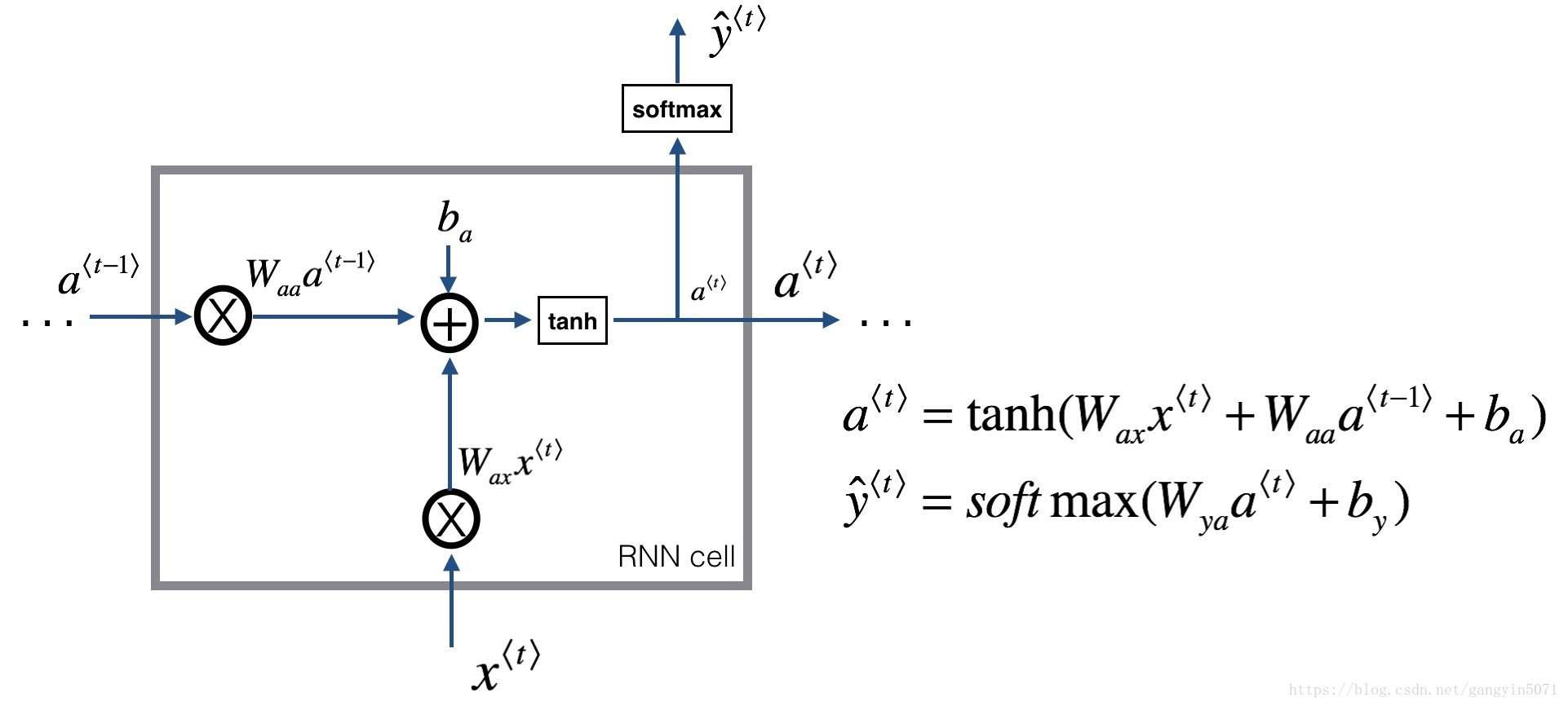
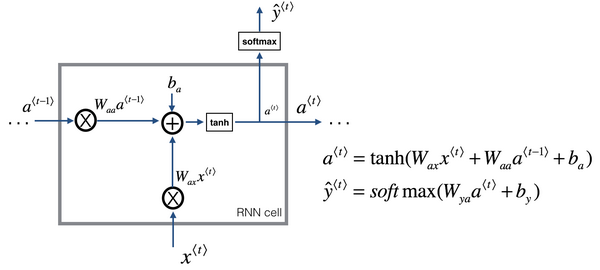
循环神经网络从左向右扫描数据,同时每个时间步的参数也是共享的,输入、激活、输出的参数对应为 $W_{ax}$、$W_{aa}$、$W_{ay}$。
- $W_{ax}$ 管理从输入 $x^{⟨t⟩}$ 到隐藏层的连接,每个时间步都使用相同的 $W_{ax}$;
- $W_{aa}$ 管理激活值 $a^{⟨t⟩}$ 到隐藏层的连接,同时每一个时间步都使用相同的参数$W_{aa}$;
- $W_{ya}$ 管理隐藏层到激活值 $y^{⟨t⟩}$ 的连接,同时每一个时间步都使用相同的参数$W_{ya}$。
用这样的符号约定来表示这些矩阵下标,举个例子 $W_{ax}$,第二个下标 $W_{ax}$意味着要乘以某个 $x$类型的量,然后第一个下标 $a$表示它是用来计算某个 $a$类型的变量。同样的,可以看出这里的$W_{ya}$乘上了某个 $a$类型的量,用来计算出某个 $\hat y$类型的量。
因此,前向传播过程如下:
- 构造初始激活函数:
- $g_1$通常选择 $tanh$ 作为激活函数,有时也会使用 $Relu$ 作为激活函数;
- 如果是二分类问题,$g_2$使用 $sigmoid$ 作为激活函数,如果是多分类问题,可以使用 $softmax$ 激活函数
为了简化表达式,可以对 $a^{⟨t⟩}$ 项进行整合:
则:
关于维数稍微啰嗦几句:
- 假如 $a^{⟨t-1⟩}$ 是 100 维, $x^{⟨t⟩}$ 是 10000 维,那么 ${W_{aa}}$ 便是 $(100,100)$ 维的矩阵, ${W_{ax}}$ 便是 $(100,10000)$ 维的矩阵。堆叠起来, $W_{a}$ 便是 $(100,10100)$ 维的矩阵。
- $\begin{bmatrix} a^{⟨t-1⟩}, x^{⟨t⟩} \end{bmatrix}^T$:表示一个 $(10100,1)$ 维的矩阵。
上述是我们单独对每个cell进行公式推导,最终整个模型的公式其实就是单个cell的循环调用,下图是单个cell的具体结构图,以及前向传播的公式,非常的简洁明了 。
对时间序列参数共享的理解
对于一个句子或者文本,那个参数可以看成是语法结构或者一般规律,而下一个单词的预测必须是上一个单词和一般规律或者语法结构向结合的。我们知道,语法结构和一般规律在语言当中是共享的,所以,参数自然就是共享的!
捏陶瓷的例子可能更容易体会共享特性对于数据量的影响,不同角度相当于不同的时刻:

- 若用前馈网络:网络训练过程相当于不用转盘,而是徒手将各个角度捏成想要的形状。不仅工作量大,效果也难以保证。
- 若用递归网络:网络训练过程相当于在不断旋转的转盘上,以一种手势捏造所有角度。工作量降低,效果也可保证。
穿越时间的反向传播(Backpropagation through time)
先来简要用语言回顾以下前向传播的过程:
- 有一个输入序列:$x^{⟨1⟩}$,$x^{⟨2⟩}$,$x^{⟨3⟩}$,……,$x^{⟨T_x⟩}$;
- 然后用$x^{⟨1⟩}$还有$a^{⟨0⟩}$计算出时间步1的激活值$a^{⟨1⟩}$,再用$x^{⟨2⟩}$,$a^{⟨1⟩}$计算出$a^{⟨1⟩}$,一直到$x^{⟨T_x⟩}$;
- 计算激活值$a$的过程,是不断循环使用参数$W_a$,$b_a$的过程。
- 有了$a^{⟨1⟩}$,神经网络就可以计算第一个预测值$\hat y^{⟨1⟩}$,接着下一个时间步,继续依次计算出$\hat y^{⟨2⟩}$,$\hat y^{⟨3⟩}$……,一直到$\hat y^{⟨T_y⟩}$:
- 为了计算出$\hat y$,需要参数$W_y$和$b_y$,它们将被用于所有这些节点。
为了进行反向传播计算,使用梯度下降等方法来更新RNN的参数,我们需要定义一个损失函数,单个位置上(或者说单个时间步上)某个单词的预测值的损失函数采用交叉熵损失函数,如下:
将单个位置上的损失函数相加,得到整个序列的成本函数如下:
然后,反向传播(Backpropagation)过程就是从右到左分别计算 $L(\hat y,y)$ 对参数 $W_{a}$ , $W_{y}$ , $b_a$ , $b_y$ 的偏导数。思路与做法与标准的神经网络是一样的。一般可以通过成熟的深度学习框架自动求导,例如PyTorch、Tensorflow等
此处给出详细的计算公式:
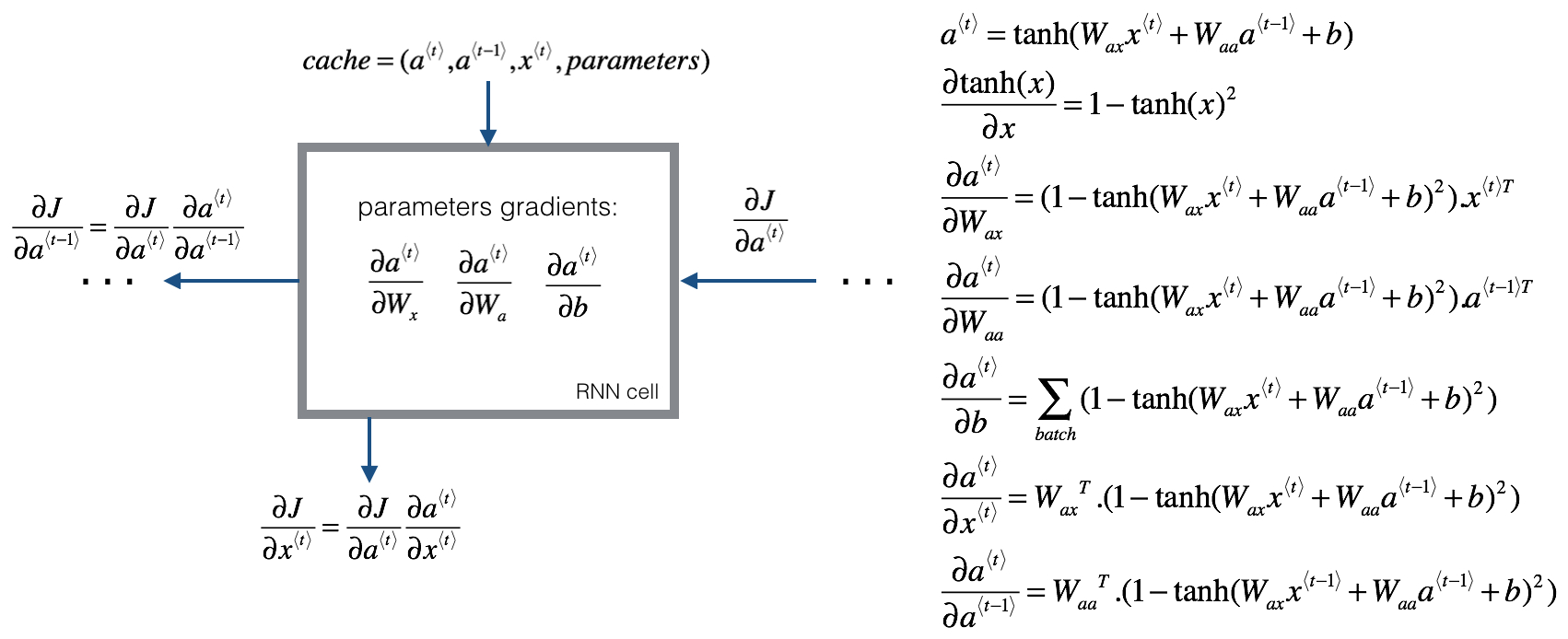
循环神经网络的反向传播被称为通过时间反向传播(Backpropagation through time),因为从右向左计算的过程就像是时间倒流。
不同类型的循环神经网络(Different types of RNNs)
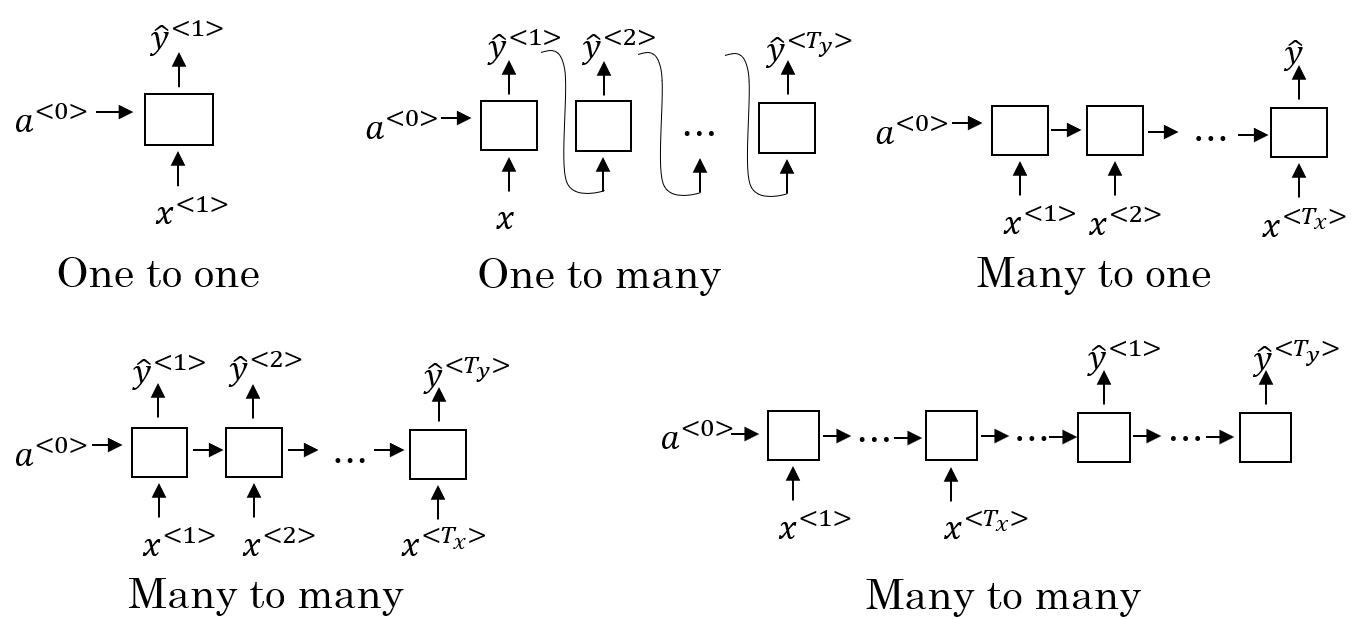
对于RNN,不同的问题需要不同的输入输出结构。
- many-to-many $(T_{x} = T_{y})$:这种情况下的输入和输出的长度相同,是上面例子的结构;
- many-to-one:如在情感分类问题中,我们要对某个序列进行正负判别或者打星操作。在这种情况下,就是输入是一个序列,但输出只有一个值;
- one-to-many:如在音乐生成的例子中,输入一个音乐的类型或者空值,直接生成一段音乐序列或者音符序列。在这种情况下,就是输入是一个值,但输出是一个序列;
- many-to-many $(T_{x} \neq T_{y})$:像机器翻译这种类似的应用来说,输入和输出都是序列,但长度却不相同,这是另外一种多对多的结构。
语言模型和序列生成(Language model and sequence generation)
在自然语言处理中,构建语言模型是最基础的也是最重要的工作之一,并且能用RNN很好地实现。那什么是语言模型?
对于下面的例子,两句话有相似的发音,但是想表达的意义和正确性却不相同,如何让我们的构建的语音识别系统能够输出正确地给出想要的输出。也就是对于语言模型来说,从输入的句子中,评估各个句子中各个单词出现的可能性,进而给出整个句子出现的可能性。
- The apple and pair salad.
- The apple and pear salad.
很明显,第二句话更有可能是正确的翻译。语言模型实际上会计算出这两句话各自的出现概率。
语音识别系统,还有机器翻译系统,它要能正确输出最接近的句子。而语言模型做的最基本工作就是输入一个句子,准确地说是一个文本序列,$y^{⟨1⟩}$,$y^{⟨2⟩}$一直到$y^{⟨T_y⟩}$。对于语言模型来说,用$y$来表示这些序列比用来$x$表示要更好,然后语言模型会估计某个句子序列中各个单词出现的可能性。
- 建立语言模型所采用的训练集是一个大型的语料库(Corpus),指数量众多的句子组成的文本。
- 建立过程的第一步是标记化(Tokenize),即建立字典;
- 然后将语料库中的每个词表示为对应的 one-hot 向量。
- 其中,未出现在字典库中的词使用“UNK”来表示;
- 另外,需要增加一个额外的标记 EOS(End of Sentence)来表示一个句子的结尾。
- 标点符号可以忽略,也可以加入字典后用 one-hot 向量表示。
将标志化后的训练集用于训练 RNN,过程如下图所示:
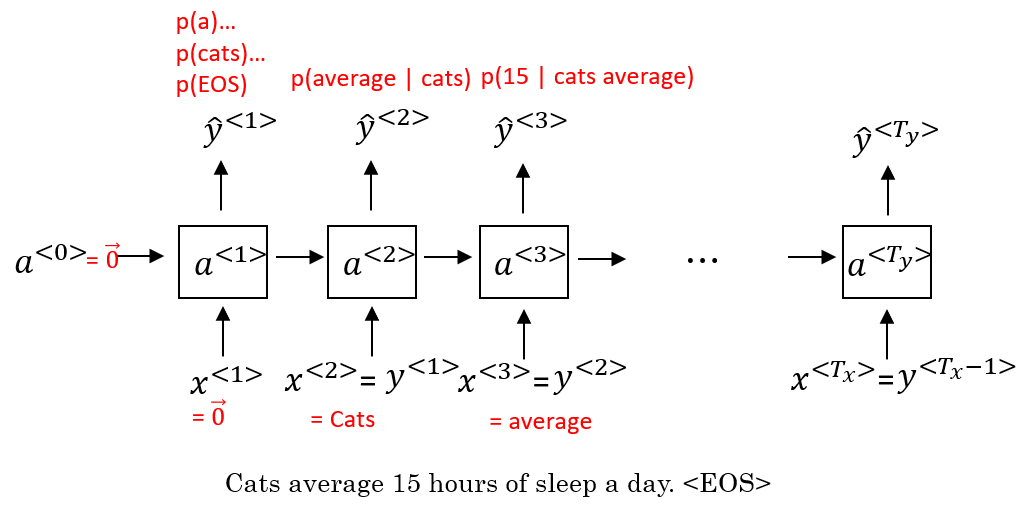
在第一个时间步中,输入的 $a^{⟨0⟩}$和 $x^{⟨1⟩}$都是零向量,$\hat y^{⟨1⟩}$是通过 softmax 预测出的字典中每个词作为第一个词出现的概率;
在第二个时间步中,输入$x^{⟨2⟩}$(训练样本的标签中的第一个单词 $y^{⟨1⟩}$(即“cats”))和上一层的激活项$a^{⟨1⟩}$,输出的 $y^{⟨2⟩}$表示的是通过 softmax 预测出的、单词“cats”后面出现字典中的其他每个词的条件概率。以此类推,最后就可以得到整个句子出现的概率。
所以RNN中的每一步都会考虑前面得到的单词,比如给它前3个单词,让它给出下个词的分布,这就是RNN如何学习从左往右地每次预测一个词。
接下来为了训练这个网络,我们要定义代价函数,于是,在某个时间步$t$,如果真正的词是$y^{⟨t⟩}$,而神经网络的softmax层预测结果值是$\hat y^{⟨t⟩}$,那么这就是softmax损失函数:
则成本函数为:
如果你用很大的训练集来训练这个RNN,你就可以通过开头一系列单词像是Cars average 15或者Cars average 15 hours of来预测之后单词的概率。现在有一个新句子(假设只有三个单词),他们是$y^{⟨1⟩}$,$y^{⟨2⟩}$,$y^{⟨3⟩}$,为了计算出这个句子中各个单词的概率,方法就是:
- 第一个softmax层会告诉你$y^{⟨1⟩}$的概率,这也是第一个输出;
- 然后第二个softmax层会告诉你在考虑$y^{⟨1⟩}$的情况下$y^{⟨2⟩}$的概率;
- 然后第三个softmax层告诉你在考虑$y^{⟨1⟩}$和$y^{⟨2⟩}$的情况下$y^{⟨3⟩}$的概率;
- 把这三个概率相乘,最后得到这个含3个词的整个句子的概率。
对新序列采样(Sampling novel sequences)
在训练一个序列模型之后,要想了解到这个模型学到了什么,一种非正式的方法就是进行一次新序列采样。
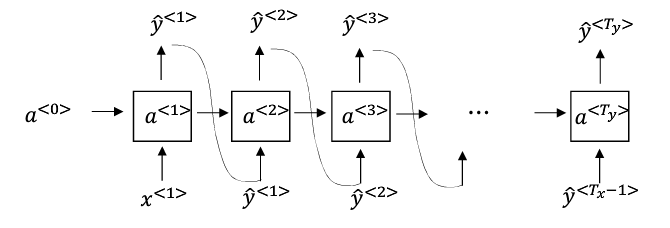
在第一个时间步输入 $a^{⟨0⟩}$和 $x^{⟨1⟩}$为零向量,输出预测出的字典中每个词作为第一个词出现的概率,根据 softmax 的分布进行随机采样(np.random.choice);将采样得到的 $\hat y^{⟨1⟩}$作为第二个时间步的输入 $x^{⟨2⟩}$;进而 softmax 层会预测下一个输出 $\hat y^{⟨2⟩}$ ,依次类推;直到采样到 EOS,最后模型会自动生成一些句子,从这些句子中可以发现模型通过语料库学习到的知识。
这里建立的是基于词汇构建的语言模型。根据需要也可以构建基于字符的语言模型,其优点是不必担心出现未知标识(UNK),其缺点是得到的序列过多过长,并且训练成本高昂。因此,基于词汇构建的语言模型更为常用。
就好像在训练的时候,喂给网络大量莎士比亚写出来的句子,网络在经过学习之后,我们就可以利用网络来随机生成句子,而这些句子是具有莎士比亚风格的句子。
循环神经网络的梯度消失(Vanishing gradients with RNNs)
基本的RNN算法还有一个很大的问题,就是梯度消失的问题。
对于以上两个句子,后面的动词单复数形式由前面的名词的单复数形式决定,句子中存在长期依赖(long-term dependencies)。但是 基本的 RNN 不擅长捕获这种长期依赖关系 。第一句话中,was受cat影响;第二句话中,were受cats影响。它们之间都跨越了很多单词。而一般的RNN模型每个元素受其周围附近的影响较大,难以建立跨度较大的依赖性。上面两句话的这种依赖关系,由于跨度很大,普通的RNN网络容易出现梯度消失,捕捉不到它们之间的依赖,造成语法错误。
虽然梯度爆炸在RNN中也会出现,但对于梯度爆炸问题,因为参数会指数级的梯度,会让我们的网络参数变得很大,得到很多的Nan或者数值溢出,所以梯度爆炸是很容易发现的,解决方法就是用梯度修剪(gradient clipping),也就是观察梯度向量,如果其大于某个阈值,则对其进行缩放,保证它不会太大。
GRU单元(Gated Recurrent Unit(GRU))
在本节中将会介绍门控循环单元,它改变了RNN的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题。
标准RNN的隐藏层单元结构如下图所示:
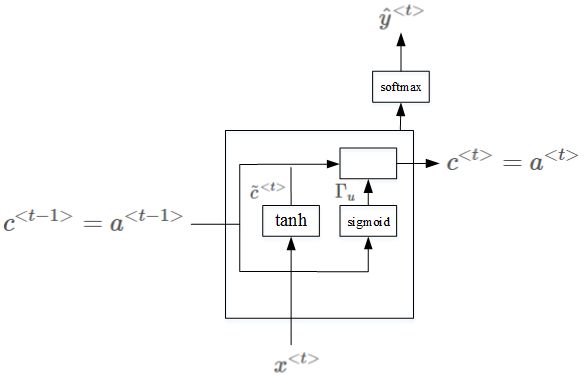
回到这个句子:
当我们从左到右读上面这个句子时,GRU 单元有一个新的变量称为 $c$,代表 记忆细胞(Memory Cell) ,其作用是提供记忆的能力,记住例如前文主语是单数还是复数等信息。在时间 $t$,记忆细胞的值 $c^{⟨t⟩}$等于输出的激活值 $a^{⟨t⟩}$;$\tilde c^{⟨t⟩}$ 代表下一个 $c$ 的候选值。$Γ_u$ 代表 更新门(Update Gate) ,用于决定什么时候更新记忆细胞的值。以上结构的具体公式为:
- 在每一个时间步上,给定一个候选值 $\widetilde c^{⟨t⟩}$ ,用以替代原本的记忆细胞 $c^{⟨t⟩}$,$c^{⟨t-1⟩}$来自上一个时刻的输出 :
- $Γ_u$的值在 0 到 1 的范围内,且大多数时间非常接近于 0 或 1,代表更新门,用以决定是否对当前时间步的记忆细胞用候选值更新替代:
- 记忆细胞的更新规则,门控值处于0-1之间,根据跟新公式能够有效地缓解梯度消失的问题:
- 其中, $c^{⟨t⟩}$、$\widetilde c^{⟨t⟩}$、${\Gamma _ u}$ 均具有相同的维度。
GRU的可视化实现如下图所示:
以上实际上是简化过的 GRU 单元,但是蕴涵了 GRU 最重要的思想。完整的 GRU 单元添加了一个新的 相关门(Relevance Gate) $Γ_r$,它负责告诉你 $\tilde c^{⟨t⟩}$ 和 $c^{⟨t⟩}$有多大的相关性。因此,表达式改为如下所示:
相关论文:
- Cho et al., 2014. On the properties of neural machine translation: Encoder-decoder approaches
- Chung et al., 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
长短期记忆(LSTM)(LSTM(long short term memory)unit)
LSTM(Long Short Term Memory,长短期记忆) 网络比 GRU 更加灵活和强大,它额外引入了 遗忘门(Forget Gate) $Γ_f$和 输出门(Output Gate) $Γ_o$。公式如下:
LSTM单元的可视化图如下所示:
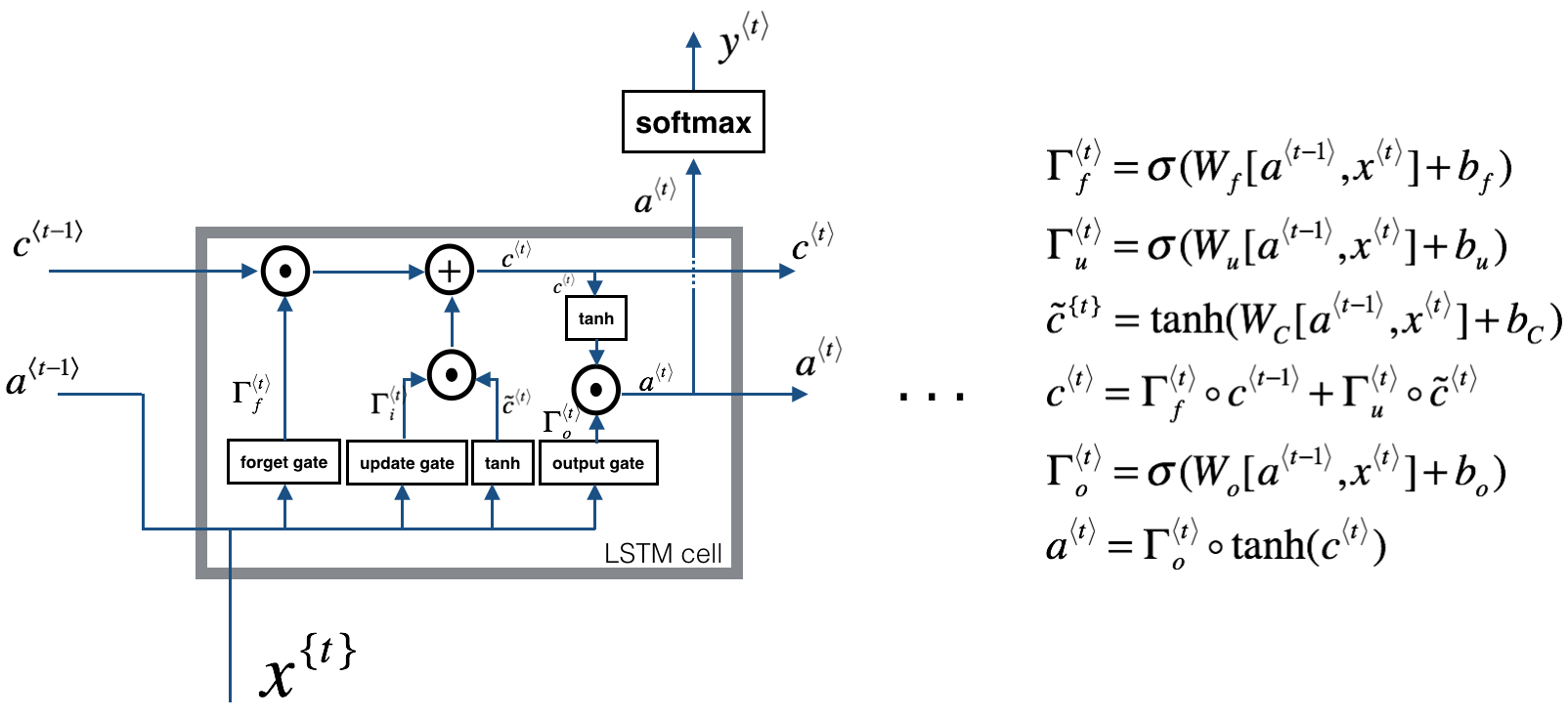
在上述公式和图示中看到,LSTM不同于GRU,$a$和$c$是独立开的两个值
将多个 LSTM 单元按时间次序连接起来,就得到一个 LSTM 网络。
以上是简化版的 LSTM。在更为常用的版本中,几个门值不仅取决于 $a^{⟨t-1⟩}$和 $x^{⟨t⟩}$,有时也可以偷窥上一个记忆细胞输入的值 $c^{⟨t-1⟩}$,这被称为 窥视孔连接(Peephole Connection) ,对LSTM的表达式进行修改:
相关论文:Hochreiter & Schmidhuber 1997. Long short-term memory
双向循环神经网络(Bidirectional RNN)
单向的循环神经网络在某一时刻的预测结果只能使用之前输入的序列信息。双向循环神经网络(Bidirectional RNN,BRNN) 可以在序列的任意位置使用之前和之后的数据。其工作原理是增加一个反向循环层,结构如下图所示:
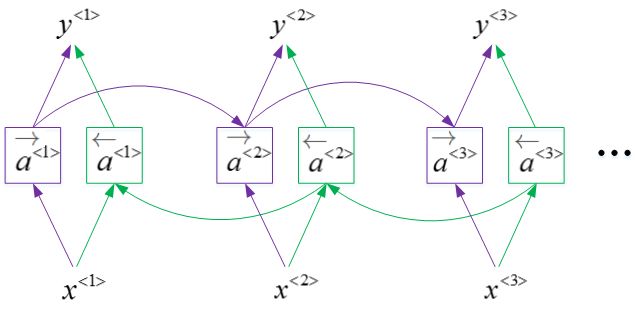
BRNN对应的输出 $y^{⟨t⟩}$ 表达式为:
这就是双向循环神经网络,并且这些基本单元不仅仅是标准RNN单元,也可以是GRU单元或者LSTM单元。事实上,很多的NLP问题,对于大量有自然语言处理问题的文本,有LSTM单元的双向RNN模型是用的最多的。所以如果有NLP问题,并且文本句子都是完整的,首先需要标定这些句子,一个有LSTM单元的双向RNN模型,有前向和反向过程是一个不错的首选。
深层循环神经网络(Deep RNNs)
循环神经网络的每个时间步上也可以包含多个隐藏层,形成深度循环神经网络(Deep RNN)。结构如下图所示:
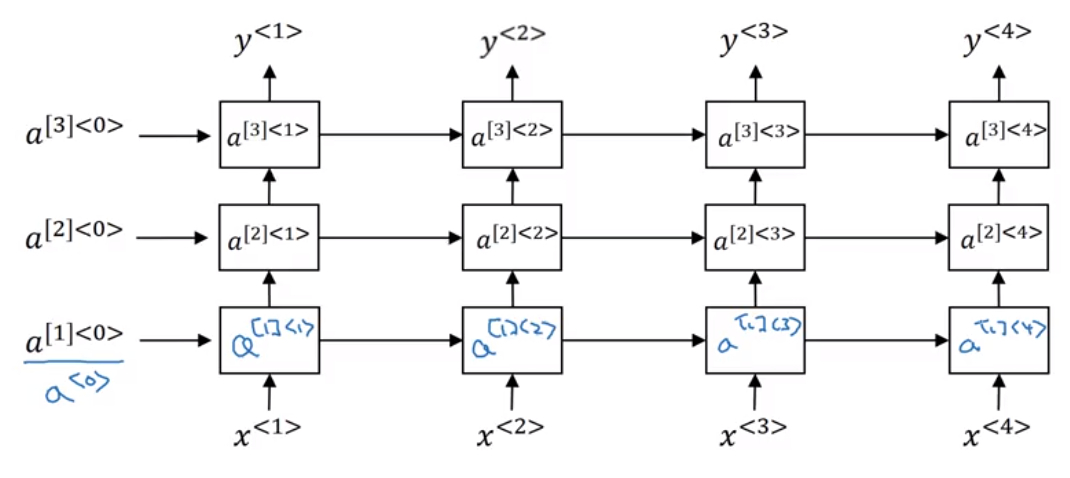
与DNN一样,用上标 $[l]$ 表示层数。Deep RNNs中 $a^{[l]⟨t⟩}$ 的表达式为:
我们知道DNN层数可达100多,而Deep RNNs一般没有那么多层,3层RNNs已经较复杂了。
另外一种Deep RNNs结构是每个输出层上还有一些垂直单元,如下图所示:
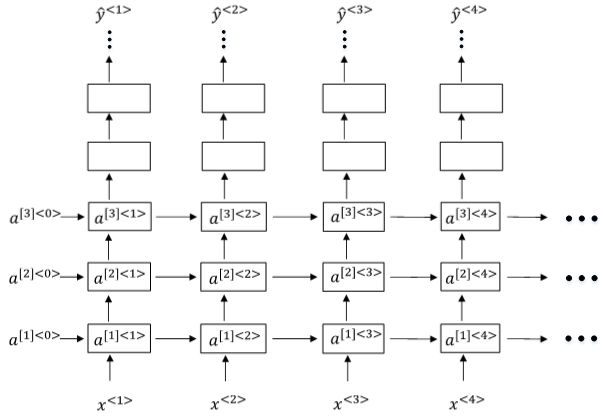
本作品采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。欢迎转载,并请注明来自:黄钢的博客 ,同时保持文章内容的完整和以上声明信息!