前言
好记性不如烂笔头,写下来的才是自己的。本篇博客将记录对抗攻击的原理。
动机
- 我们不仅希望在实验室中部署机器学习分类器,也希望在现实世界中部署机器学习分类器。
- 分类器对噪声有很强的鲁棒性,并且“大多数时间”都能工作,但这是不够的。
- 我们希望模型不仅强,还要能够能够对抗人类特意的恶意攻击。
- 特别适用于垃圾邮件分类、恶意软件检测、网络入侵检测等。
这就是为什么我们要研究如何攻击一个模型,和研究如何防御来自未知的模型攻击。
白盒攻击理论
我们想要做的事情就是,想要在真实图片 $x^0$ 上面加上一些特意设计的噪声 $\Delta x$ 得到 ${x}’ $,使得模型网络能够完全得出不一样的识别结果。
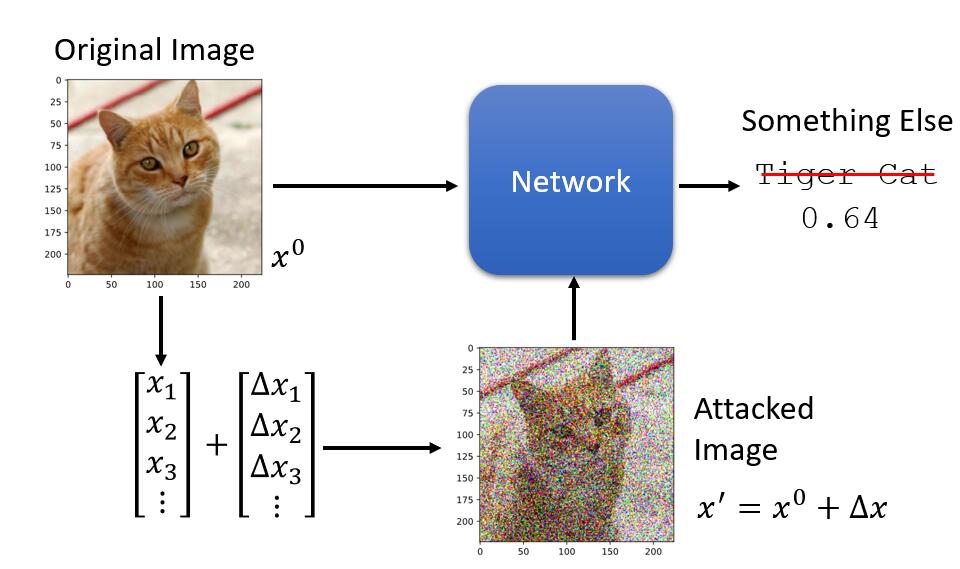
现在的重点就是,如何找出这个特别的 ${x}’$,我们现在先来看一下一般的训练网络的过程:

如上图所示,我们有一个 $x^0$ 作为输入图片,经过网络模型 $f_{\theta }(x)$ 得到一个预测输出 $y^0$。而我们期望其与真实标签 $y^{true}$ 足够接近。为此我们要做的就是最小化预测标签和真实标签的损失。因此损失函数可以表示为:
那么,在对模型的攻击中我们如何做呢?攻击分为两种,一种是无目标的攻击;一种是有目标的攻击。
我们先来看第一种,没有目标的攻击。
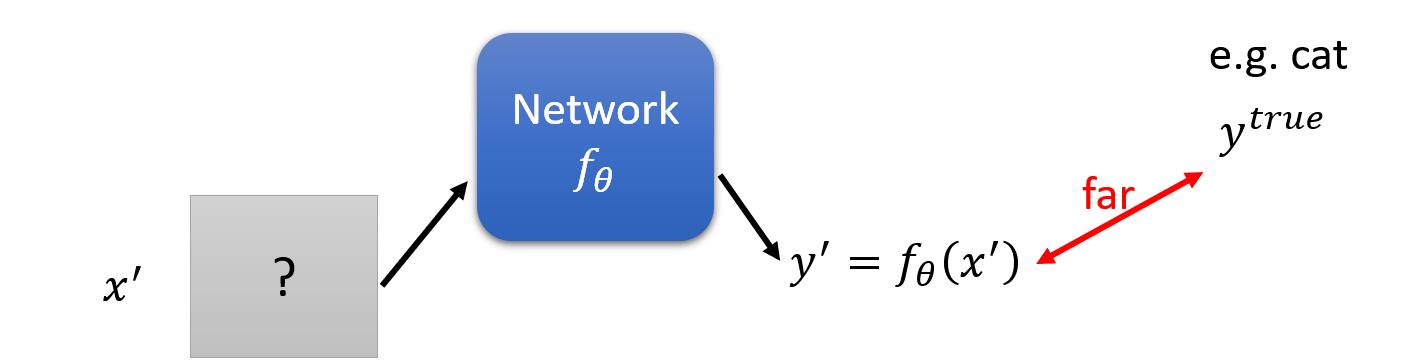
那什么叫无目标的攻击呢?意思是:我们希望找到一个未知的图片 ${x}’$ ,经过网络模型 $f_{\theta }({x}’)$ 得到一个预测输出 ${y}’$,而我们期望其与真实标签 $y^{true}$ 足够无关。为此我们要做的就是最小化预测标签和真实标签的损失的负值。因此损失函数变为:
见上式,我们可以发现需要的优化的变量由 $\theta$ 变成了 ${x}’$ ,这是因为我们攻击的网络是别人已经训练好的,即 $\theta$是不会变的了,我们唯一能做的就是通过最小化损失函数,来找到一张能够让预测标签和真实标签足够无关的 ${x}’$。
那第二种攻击情况,有目标的攻击。其意思是:我们希望找到未知的图片 ${x}’$ ,经过网络模型 $f_{\theta }({x}’)$ 得到一个我们希望的一个预测输出 ${y}’$,而该预测输出与真实标签 $y^{true}$ 无关,同时该输出 ${y}’$ 尽量和错误分类 $y^{false}$ 足够接近,如下图。
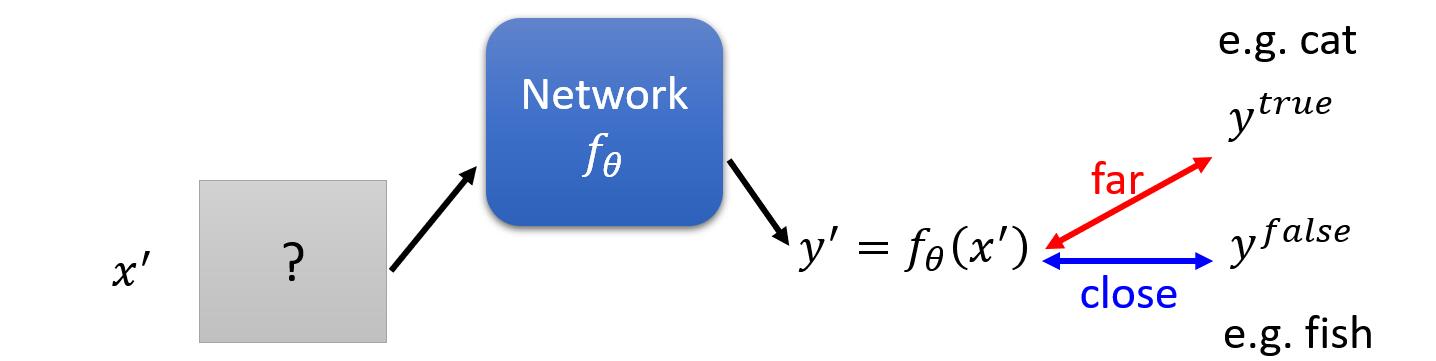
那么此时需要最小化的损失函数变成了:
但是,作为对抗攻击,我们有一个额外的限制,那就是我们通过训练找出来的输入图片 ${x}’$ 和真实图片足够接近。换句话说,我们希望找出来的图片和真实图片肉眼看起来很相似,但是一旦放入神经网络识别器里,得出的却是错误答案。因此,真实图片 $x^{0}$ 和输入图片 ${x}’$ 的距离应该小于某一个阈值,该限制被表述为:
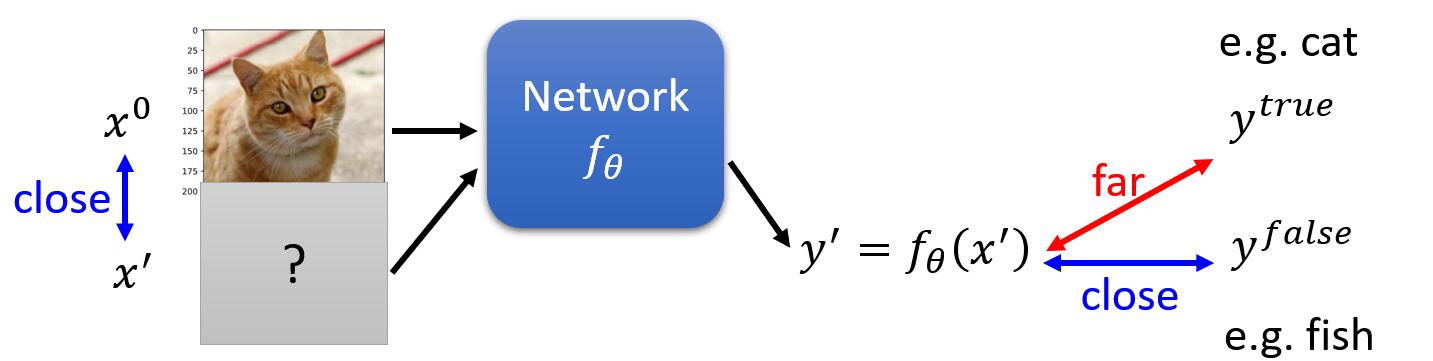
那么我们如何定义这个图片间的距离 $d$ 呢?
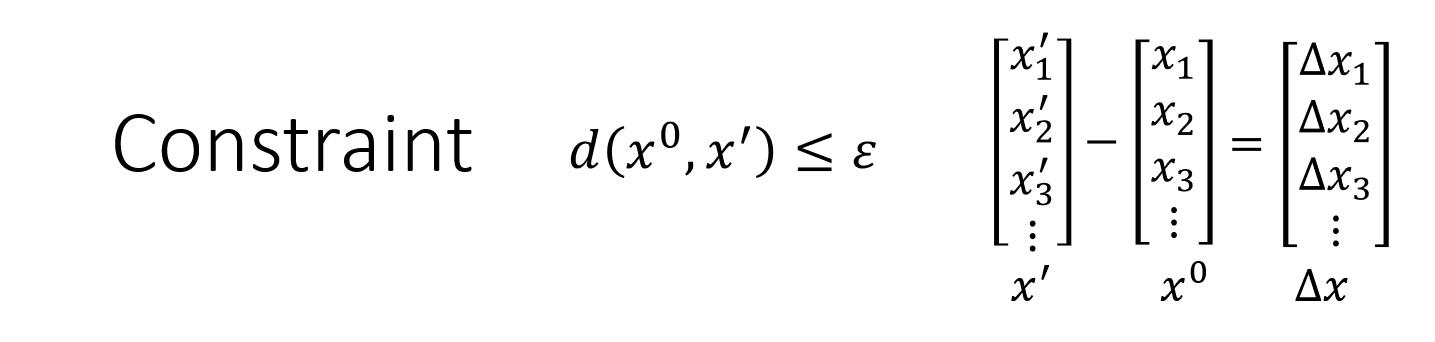
我们有两种常见的方式:L2-norm 和 L-infinity,我们用 ${x}’$ 和 $x^{0}$ 的差值 $\Delta x$ 来表示两者之间的差异。
第一种 L2-norm:
第二种 L-infinity:
因此,如何得到一张符合要求的图片 ${x}’$ ,训练方式一般地训练神经网络的方式类似:
我们需要去最小化 $L$ 来找到一个 ${x}’$,同时其满足 $d(x^{0},{x}’)\leq \varepsilon$ 的限制条件,我们用梯度下降的具体做法:

至于限制条件,我们在梯度下降的迭代过程中,检查得到的新的 $x^t$ 是否满足限制条件,如果不满足限制条件,我们通过 $fix()$ 函数来修正它。该函数的目标是修改超出限制的 $x^t$,使得 $x^t$ 和 $x^0$ 的距离小于超参数 $\varepsilon$。具体的做法是,$fix()$ 穷举出在 $x^0$ 里边符合限制条件的所有的像素点 $x$ ,然后我们将每一个超出限制的像素点用和它最接近的符合限制的像素点的值替代即可。
具体到 L2-norm 中就是:我们有一个输入 $x^0$,我们希望所有更新得到的值,均在圈圈以内(满足限制条件)。如果此时当我们通过梯度下降算法,得到一个 $x^t$ (蓝色的点)是在圈圈之外(不符合限制条件),那么我们就用一个符合限制条件的并和 $x^t$ 最接近的点来替代 $x^t$(蓝色的点),最终得到新的 $x^t$ (橙色的点)。
具体到 L-infinity 也是一样的。
常见文献:
FGSM (https://arxiv.org/abs/1412.6572)
Basic iterative method (https://arxiv.org/abs/1607.02533)
L-BFGS (https://arxiv.org/abs/1312.6199)
Deepfool (https://arxiv.org/abs/1511.04599)
JSMA (https://arxiv.org/abs/1511.07528)
C&W (https://arxiv.org/abs/1608.04644)
Elastic net attack (https://arxiv.org/abs/1709.04114)
Spatially Transformed (https://arxiv.org/abs/1801.02612)
One Pixel Attack (https://arxiv.org/abs/1710.08864)
黑盒攻击理论
上述的内容其实都是白盒攻击的理论,即,上述方法成功的前提都是我们知道了要被攻击的模型网络的具体参数,但是往往很多时候,我们是不知道模型的参数的。那我们面对这种不知道模型参数的情况,我们如何做攻击呢?
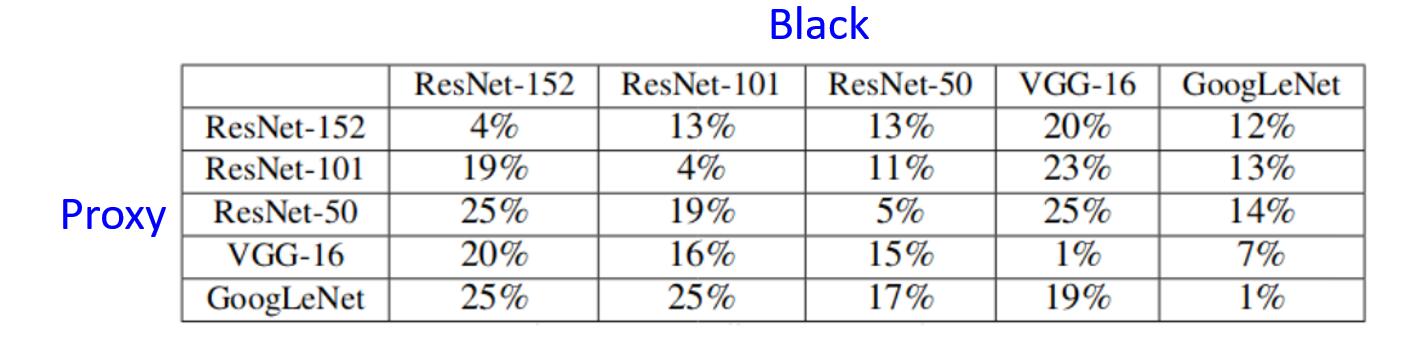
原理其实很简单,虽然我们不知道具体的模型参数架构,但是往往我们能够知道该模型是用何种数据集训练得到的。我们要做的就是先根据这个数据集训练出一个我们自己的模型。然后我们按照白盒攻击的方式来攻击这个我们自己的模型,得到攻击样本。
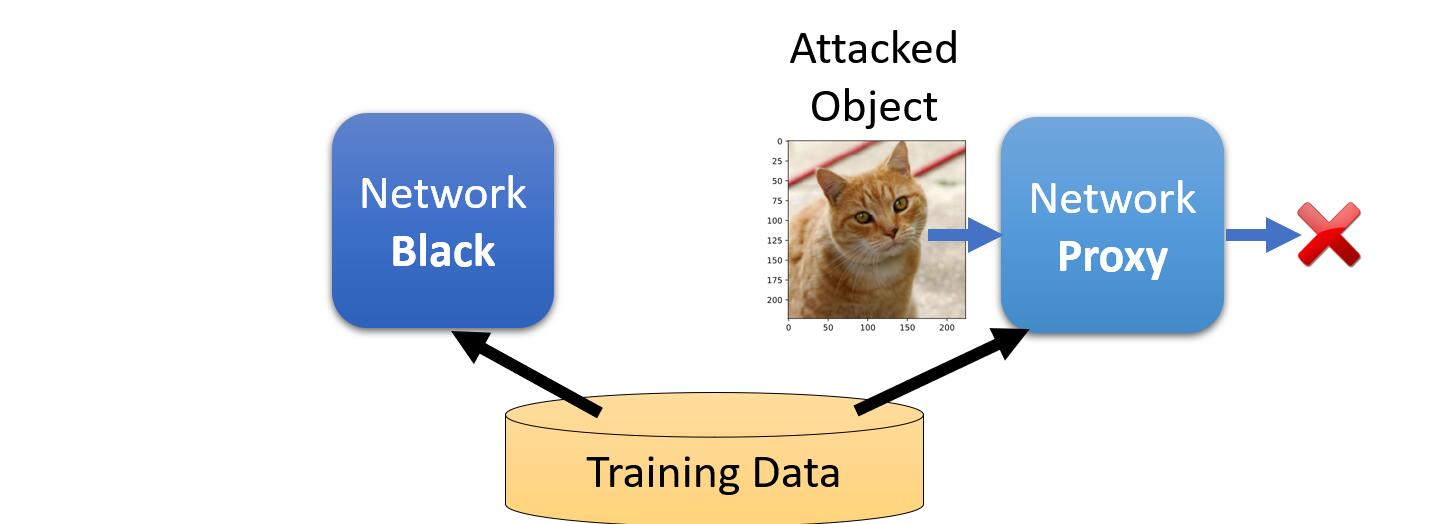
然后我们通过得到的攻击样本去攻击真正的模型,这个过程通常是奏效的。
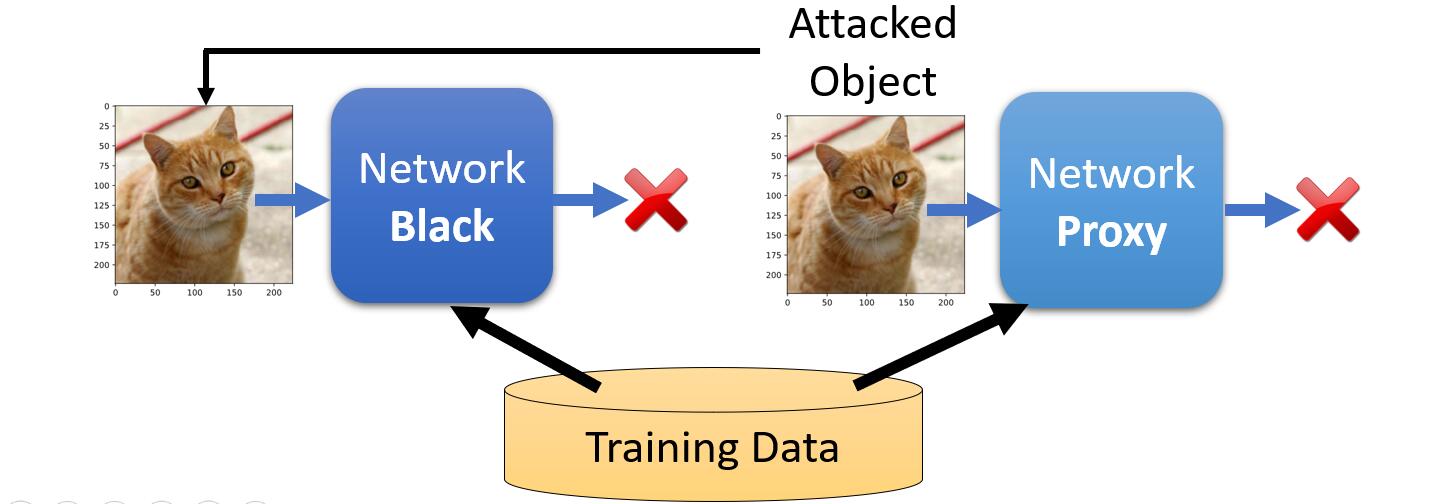
同时,文献中的实验还得出结论,通常一张攻击图片如果对一种模型架构起作用得话,也意味着同样地对其他模型架构起作用 https://arxiv.org/pdf/1611.02770.pdf。
本作品采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。欢迎转载,并请注明来自:黄钢的博客 ,同时保持文章内容的完整和以上声明信息!