前言
本篇博客是 Andrew NG 《Machine Learning Yearning》 的「第十章:根据组件执行误差分析」翻译。本章学习到如何进行机器学习管道的误差分析,如何利用复杂系统的组件来为误差分析提供帮助。开启本章内容,出发!
👉官网传送门
👉GitHub 项目传送门,欢迎 Star
53. 根据组件执行误差分析
假设你的系统是使用复杂的机器学习管道构建的,并且希望提高系统的性能,那么你应该对整个机器学习管道的哪一个部分进行改进呢?通过将错误归因于管道的特定部分,你可以决定如何确定工作的优先级。
让我们以我们的暹罗猫分类器作为示例:

第一部分是猫分类器,负责探测图片中猫咪部分并把它们抠出来;第二部分是猫的品种分类器,用来判定抠出来的猫图是否是暹罗猫品种。改进两个组件中的任何一个都可能花费你数年的时间,那么你该决定关注哪个(些)组件呢?
通过根据组件执行误差分析,你可以尝试将算法所犯的每个错误归因于管道的两个部分中的一个(或两个)。例如:某张图片样本的正确标签为含有暹罗猫($y=1$),算法却将其标签误分类为不含有暹罗猫($y=0$)。

让我们手动检查算法两个步骤的执行过程,假设猫检测器从下图中检测出一只猫:

这意味着下图将作为猫咪品种分类器的输入:

接下来,猫品种分类器将该输入正确分类为不包含暹罗猫。因此,作为猫品种分类器而言,输入包含一堆岩石的图片并输入一个 $y=0$ 的标签是没问题的。实际上,作为人而言,如果给出这样的图片,也会把它标签标定为 $y=0$ 。因此,我们就可以得出,整个猫分类器管道出问题的地方在第一部分——猫探测器。
另一方面,如果猫探测器输出了以下边界框:

你会得出如下结论,猫探测器是工作正常的,并且我们可以将出问题的组件定位在猫品种分类器上。
假设你遍历100个错误分类的开发集图像,并发现90个错误可归因于猫探测器,只有10个错误可归因于猫品种分类器。 那么你可以有把握地得出结论:应该更加关注如何改进猫探测器。
到目前为止,我们关于如何将误差归因于管道的某个组件的描述是非正式的:你查看每个部分的输出,看看是否可以决定哪个部分出错了。这种非正式的方法可能就是你所需要的。但在下一章中,你还将看到一种更正式的误差归因方式。
54. 将误差归因到某个组件
让我们继续使用这个例子:
假设猫检测器输出了这样的边界框:

被裁减的图片将会作为猫品种分类器的输入,因此它给出了错误的分类结果 $y=0$, 即图片中没有猫。

猫检测器的效果很糟糕。然而,一个技术娴熟的人仍然可以从这糟糕的裁剪图像中识别出暹罗猫。那么我们是否将此误差归因于猫检测器或猫品种分类器两者之一,或两者兼而有之? 答案是模棱两可的。
如果像这样的模糊情况的数量很少,你可以做出你想要的任何决定并获得类似的结果。但是这里有一个更正式的测试方法,可以让你更明确地将错误归因于一个组件:
- 用手动标记的边界框替换猫检测器的输出;
- 通过猫品种分类器处理相应的裁剪图像。如果猫品种分类器仍将其错误地分类,则将误差归因于猫品种分类器。否则,将此误差归因于猫检测器;

换句话说,跑一个实验,在其中为猫品种分类器提供「完美」输入,则会出现两种情况:
- 情况1:即使给出了一个「完美」的边界框,猫品种分类器仍然错误地输出 $y = 0$。 在这种情况下,很明显猫品种分类器是有问题的;
- 情况2:给定一个「完美」的边界框,品种分类器现在正确输出 $y = 1$。这表明如果只有猫探测器给出了一个更完美的边界框,那么整个系统的输出就是正确的。因此,我们将错误归因于猫探测器。
通过对开发集中误分类的图像执行此分析流程,你现在可以明确地将每个错误归因于一个组件。这允许你对整个管道的每个组件引起的错误程度进行分析,从而决定将注意力集中在哪一块。
55. 误差归因的一般情况
以下是误差归因的一般步骤。假设管道有三个步骤 A,B 和 C,其中 A 直接输入到 B,B 直接输入到 C。

对于系统在开发集上存在的每个错误样本:
- 尝试手动修改 A 的输出为 「完美」 输出(例如,猫的 「完美」 边界框),并在此输出上运行管道其余的 B,C 部分。 如果算法现在给出了正确的输出,那么这表明,只要 A 给出了更好的输出,那么整个算法的输出就是正确的;因此,你可以将此误差归因于组件 A。 否则,请继续执行步骤 2。
- 尝试手动修改 B 的输出为 「完美」 输出。如果算法现在给出正确的输出,则将误差归因于组件 B。否则,继续执行步骤 3。
- 将误差归因于组件 B。
让我们来看一个复杂一点的例子:
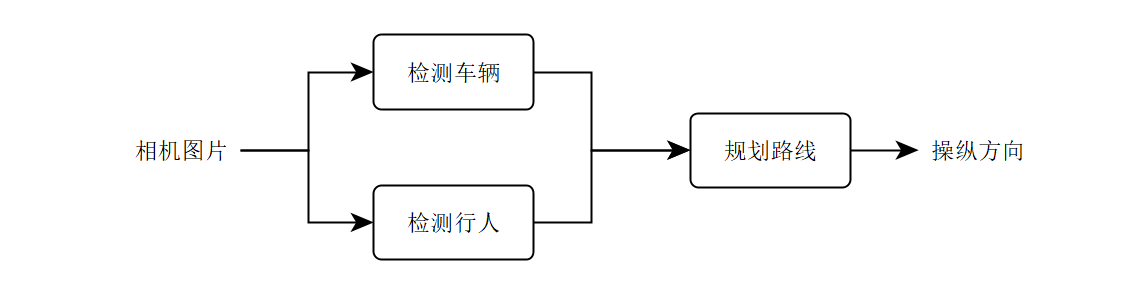
如上图所示,你的自动驾驶汽车算法使用上述管道。 如何根据组件的错误分析来决定要关注哪个(些)组件呢?
你可以将三个组件映射到 A, B, C,如下所示:
- A:检测汽车
- B:检测行人
- C:规划汽车路径
按照上述程序,假设你在封闭的轨道上对你的汽车进行测试的时候出现这种情况:汽车选择了一个比熟练司机更激进的转向方向。在自动驾驶领域,这种情况通常被称为场景(scenario)。接着你需要:
- 尝试手动修改 A (检测汽车)的输出,使之成为 「完美」 输出(例如,手动干预并告诉它其他汽车在哪里)。然后像之前一样运行管道其余的 B 和 C 部分,同时允许 C (规划路径)使用 A 现在的完美输出。如果发现算法为汽车规划出一条更好的路径,那么表明,如果 A 给出更好的输出,整个算法的输出会更好;因此,你可以将此误差归因于组件 A。否则,继续执行步骤 2。
- 尝试手动修改 B(检测行人)的输出,使之成为 「完美」 输出。如果算法最终给出正确的输出,则将错误归因于组件 B.否则,继续执行步骤3。
- 将误差归因于组件 C。
机器学习管道的组件应该根据有向无环图(DAG)排序,这意味着你应该能够以一些固定的从左到右的顺序计算它们,后面的组件应仅依赖于早期组件的输出。只要组件 A -> B -> C顺序的映射遵循 DAG 排序,那么误差分析就没问题。但是假设你交换了 A 和 B,那么结果可能略有不同:
- A:检测行人(以前是检测汽车)
- B:检测汽车(以前是检测行人)
- C:规划汽车路径
但是这种分析的结果仍然是有效的,并能为你的注意力集中在哪里提供了良好的指导。
56. 组件误差分析与人类效率的比较
对学习算法进行误差分析就像使用数据科学来分析机器学习系统的误差,目的是作出有关下一步该做什么的决策。从最基本的角度来看,组件的误差分析最重要的是告诉了我们哪些组件的是最值得努力改进的。
假设你有一个关于客户在网上购物的数据集。数据科学家可能有许多不同的方法来分析数据,并可能会得出许多不同的结论:关于网站是否应该提高价格?关于是否应该通过不同营销活动获得的客户的终身价值等等。在这里,分析数据集的方法没有所谓的正确与否,不同的方法都有可能得出有用的决策。同样,也没有一种绝对「正确」的方法来进行误差分析。通过这些章节,你已经学习了许多最常见的设计模式,可以用于分析机器学习系统并得出有利于优化系统的决策,当然你也可以自由地尝试其他分析误差的方法。
让我们回到自动驾驶的应用程序中来,其中汽车检测算法输出附近汽车的位置(可能是速度),行人检测算法输出附近行人的位置,这两个输出最终被用于为这辆车规划行驶路线。
如果想要调试该机器学习管道,却不希望严格遵循上一章中提到的过程,你可以非正式地询问:
- 在检测汽车时,汽车检测组件与人类水平表现相差多少?
- 在检测行人时,行人检测组件与人类水平表现相差多少?
- 整个系统的性能与人类表现相差多少?在这里,人类水平的表现假定:人类必须仅根据前两个组件的输出(而不是根据摄像机图像)来规划汽车的路径。换句话说,当人类只得到相同的输入时,路径规划组件的性能与人类的性能相较如何?
如果你发现其中一个组件的性能表现远低于人类水平表现,那么应该专注于提高该组件的性能。
许多的误差分析过程在我们去尝试自动化人类所做的工作的时候效果最好,因此可以针对人类水平表现进行基准测试。我们前面的大多数例子都有这个隐式假设。如果你正在构建一个机器学习系统,其中的最终输出或一些中间组件正在做一些连人类都做不到的事情,那么上述一些过程将不适用。
总而言之,这是处理人类可以解决的问题的另一个优势——你有更强大的误差分析工具,因此你可以更有效地为团队的工作标定优先级。
57. 发现有缺陷的机器学习管道
如果机器学习管道的每个单独组件的性能都达到了人的水平或接近人的水平,但是管道的整体性能却远远低于人的水平,这通常意味着管道有缺陷,需要重新设计。误差分析还可以帮助你了解是否需要重新设计管道。
在前一章中,我们有讨论到这三个部分组件的表现是否达到人类水平的问题。假设所有三个问题的答案都是肯定的,也即是系统满足:
- 汽车检测部件在用于从摄像机图像中检测汽车中(大概)达到人类级别的性能;
- 行人检测组件在用于从摄像机图像中检测汽车中(大概)达到人类级别的性能;
- 路线规划组件能达到和利用前两个组件的输出(而不是根据摄像机图像)来规划汽车的路径的专业人士相当的性能表现。
然而,你的自动驾驶汽车系统的整体性能远远低于人类水平。换句话说,能够访问摄像机图像的人可以为汽车规划出明显更好的路径。据此你能得出什么结论?
唯一可能的结论是机器学习管道结构存在缺陷。在这种情况下,规划路径组件在给定其输入的情况下运行得很好,但是输入并没有包含足够的信息。此时应该问问自己,除了前面两个管道组件的输出之外,还需要什么其他信息才能很好地规划汽车行驶的路径。换句话说,一个熟练的驾驶员还需要什么其他信息?
例如,假设你意识到人类驾驶员还需要知道车道标记的位置,这建议你应该重新设计管道如下1:
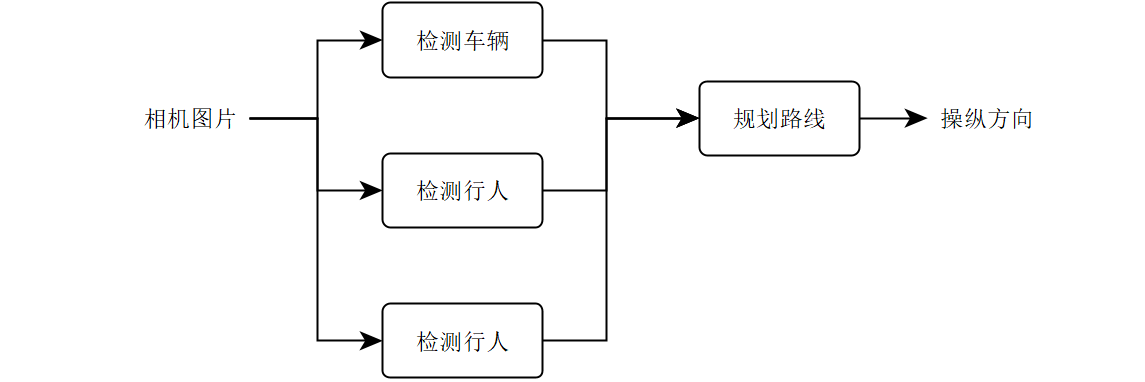
最后,如果你认为,即使在每个组件都具有人类级别的性能的情况下(请记住,你是在和与管道组件具有相同输入的人进行比较),管道整体上也不会达到人类水平的性能,则表明管道有缺陷,应该重新设计。
本书结语
恭喜你完成这本书的阅读!
在第 2 章中,我们讨论了本书如何帮助你成为团队的超级英雄。
唯一比成为超级英雄更好的事情就是成为超级英雄团队的一员。我希望你能把这本书的分享给你的朋友和队友,并帮助他们成为超级英雄!
-
在上面的自动驾驶案例中,理论上,我们可以通过将原始相机图像直接输入规划组件来解决这个问题。但是,这违反了第 51 节中描述的「任务简单性」的设计原则,因为路径规划模块现在需要输入原始图像,并且有一个非常复杂的任务需要解决。这就是为什么添加一个检测车道标记组件是一个更好的选择的原因——它有助于将重要的和以前缺少的有关车道标记的信息提供给路径规划模块,同时可以避免使任何特定模块过于复杂而变得无法构建/训练。 ↩
本作品采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。欢迎转载,并请注明来自:黄钢的博客 ,同时保持文章内容的完整和以上声明信息!