前言
听说Mnist在Deeplearning界享有‘Hello World’般地位,现对此在 Windows Caffe 下的操作做简要记录!
Windows 下的 Caffe 环境配置—–“Caffe for Windows10”
mnist手写数字数据集获取
THE MNIST DATABASE of handwritten digits
将该网址下的四个压缩包全部下载到本地。
train-images-idx3-ubyte.gz: training set images (9912422 bytes)
train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
上述四个压缩包压缩到路径 D:\GitHub Repository\caffe\data\mnist。
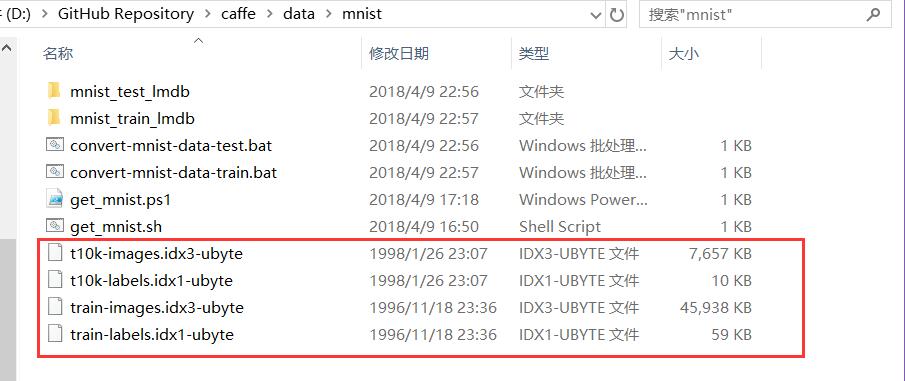
在当前目录下新建 convert-mnist-data-test.txt 保存,然后重命名为 convert-mnist-data-test.bat,双击运行,即将test数据集转换为LMDB格式的文件,转换出来的文件存放在当前路径下的 mnist_test_lmdb 文件下:
..\..\build\x64\install\bin\convert_mnist_data.exe --backend=lmdb t10k-images.idx3-ubyte t10k-labels.idx1-ubyte mnist_test_lmdb
Pause
在当前目录下新建 convert-mnist-data-train.txt 保存,然后重命名为 convert-mnist-data-train.bat :
..\..\build\x64\install\bin\convert_mnist_data.exe --backend=lmdb train-images.idx3-ubyte train-labels.idx1-ubyte mnist_train_lmdb
pause
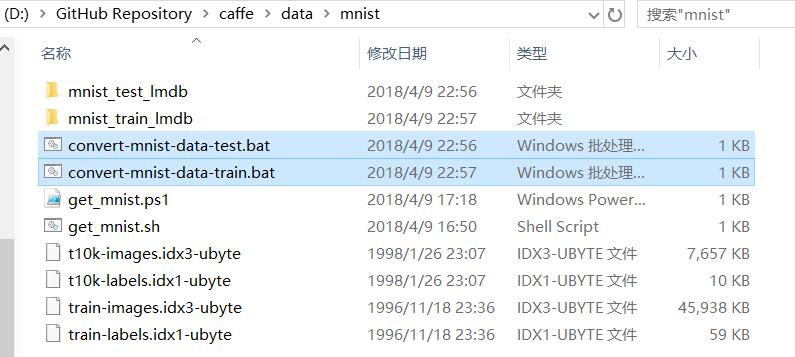
对上述两段指令,做解释,这里以第一段示例,第二段格式是一样的:
..\..\作用是cd到caffe的根目录,因为当前目录是在caffe\data\mnist,也就是在根目录下的ild\x64\install\bin\找到之前编译好的转换mnist数据集的程序convert_mnist_data.exe;--backend=lmdb指定转换数据集为 LMDB 格式,还有一种是 LEVELDB,这里没有使用。t10k-images.idx3-ubyte t10k-labels.idx1-ubyte为将要被转换的数据集,因为这两个文件放在当前路径,所以直接指定名称就可以了。mnist_test_lmdb这个是输出数据的路径,这里我是打算生成在当前路径下。- 这里备注下:在指定exe文件时,语句中使用的是windows下的路径格式,使用反斜杠
\或者//,而之后的命令可以使用\,/,看心情。
其实第一个路径就是 exe 文件所在路径, 中间指定转换的数据类型,后面两个就是数据所在路径,最后一个是输出文件路径。
当然也可以全部语句写在一个脚本上,并使用if语句做判断:
REM 设置DATA和TOOLS路径
set DATA=../../data/mnist
set TOOLS=..\..\build\x64\install\bin
REM 设置要生成的数据格式,'REM'作用是注释该条语句
REM set BACKEND=leveldb
set BACKEND=lmdb
if exist mnist_train_%BACKEND%(
echo "exist mnist_train_%BACKEND%"
) else (
echo "Creating %BACKEND%..."
"%TOOLS%\convert_mnist_data.exe" %DATA%/train-images.idx3-ubyte %DATA%/train-labels.idx1-ubyte mnist_train_%BACKEND% --backend=%BACKEND%
"%TOOLS%\convert_mnist_data.exe" %DATA%/t10k-images.idx3-ubyte %DATA%/t10k-labels.idx1-ubyte mnist_test_%BACKEND% --backend=%BACKEND%
)
echo "Done."
pause
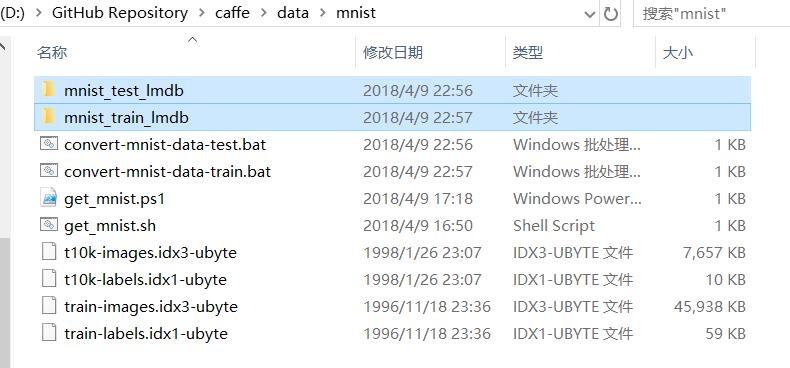
生成结果:
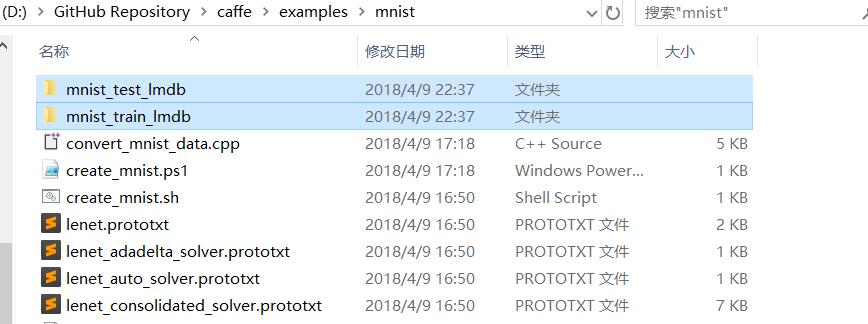
将生成的两个文件夹 mnist_test_lmdb 和 mnist_test_lmdb copy到 D:\GitHub Repository\caffe\examples\mnist 下。
训练数据前的参数修改
关注 D:\GitHub Repository\caffe\examples\mnist下的两个文件 lenet_solver.prototxt 和 lenet_train_test.prototxt。
第一个 lenet_solver.prototxt 这个文件是具体的训练网络的引入文件,定义了CNN网络架构之外的一些基础参数,如总的迭代次数、测试间隔、基础学习率、基础学习率的更新策略、训练平台(GPU或CPU)等。
//对训练和测试网络的定义,网络的路径,可以使用绝对路径或者相对路径
net: "examples/mnist/lenet_train_test.prototxt"
//test_iter参数定义训练流程中前向传播的总批次数,在MNIST中,定义的是每批次100张图片,一共100个批次,覆盖了全部10000个测试图例
/*
test_iter是定义的测试图例分为多少批次,由于一次性执行所有的测试图例效率很低,所以把测试
图例分为几个批次来依次执行,每个批次包含的图例数量是在net网络的模型文件.prototxt中的
batch_size变量定义的,test_iter*batch_size等于总的测试图集数量
*/
test_iter: 100
//测试间隔,训练没迭代500次后执行一次测试(测试是为了获得当前模型的训练精度)
# Carry out testing every 500 training iterations.
test_interval: 500
/*
网络的学习率设置
1. base_lr:表示base learning rate,基础学习率,一般在网络模型中的每一层都会定义两个名称为
“lr_mult”的学习率系数,这个学习率系数乘上基础学习率(base_lr*lr_mult)才是最终的学习率
2. momentum:冲量单元是梯度下降法中一种常用的加速技术,作用是有助于训练过程中逃离局部
最小值,使网络能够更快速的收敛,具体的值是经过反复的迭代调试获得的经验值
3. weight_decay:权值衰减的设置是为了防止训练出现过拟合,在损失函数中,weight_decay是放
在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度。weight_decay可以调节
模型复杂度对损失函数的影响,提高模型的泛化能力
*/
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
/*
学习率修改策略
以上设置的是初始学习率参数,在训练过程中,依据需要,可以不断调整学习率的参数,调整的策略是
通过lr_policy定义的
lr_policy可以设置为下面这些值,相应的学习率的计算为:
- fixed: 保持base_lr不变.
- step: 如果设置为step,则还需要设置一个stepsize, 返回 base_lr * gamma ^ (floor(iter / stepsize)),其中iter表示当前的迭代次数
- exp: 返回base_lr * gamma ^ iter, iter为当前迭代次数
- inv: 如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power)
- multistep: 如果设置为multistep,则还需要设置一个stepvalue。这个参数和step很相似,step是均匀等间隔变化,而multistep则是根据stepvalue值变化
- poly: 学习率进行多项式误差, 返回 base_lr (1 - iter/max_iter) ^ (power)
- sigmoid: 学习率进行sigmod衰减,返回 base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
*/
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
//每迭代100次显示一次执行结果
# Display every 100 iterations
display: 100
//最大迭代次数
# The maximum number of iterations
max_iter: 10000
//生成中间结果,记录迭代5000次之后结果,定义caffeModel文件生成路径
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
//运行模式,CPU或者GPU
# solver mode: CPU or GPU
solver_mode: GPU
Caffe框架下的lenet.prototxt定义了一个广义上的LeNet模型,对MNIST数据库进行训练实际使用的是lenet_train_test.prototxt模型,lenet_train_test.prototxt模型定义了一个包含2个卷积层,2个池化层,2个全连接层,1个激活函数层的卷积神经网络模型,模型如下:
通过 Caffe 自带的 prototxt 文件可视化python脚本来将 lenet.prototxt 可视化直观感受下:
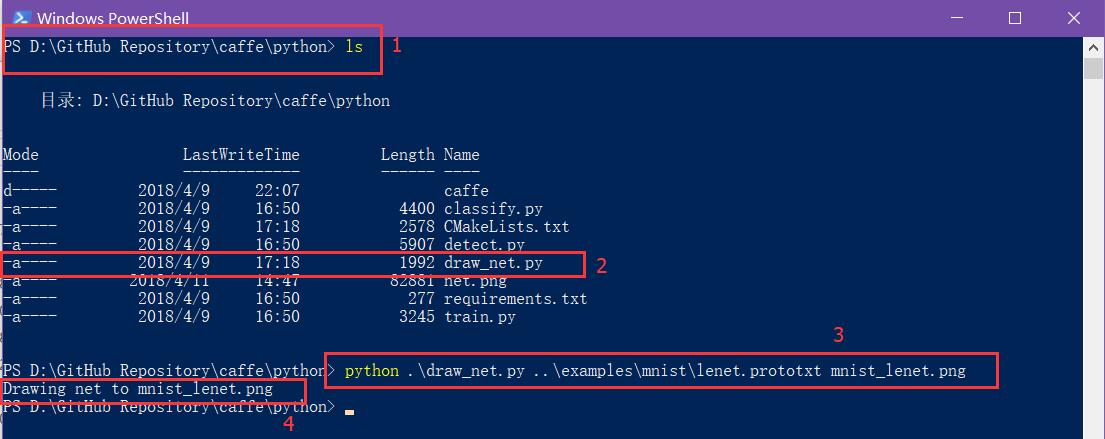
- cd 到
D:\GitHub Repository\caffe\python - ls 查看,发现 文件
draw_net.py - 敲入命令
python .\draw_net.py ..\examples\mnist\lenet.prototxt mnist_lenet.png。 - 在
D:\GitHub Repository\caffe\python生成文件mnist_lenet.png.

同样的我们生成 lenet_train_test.prototxt 的可视化结构图片。

重点关注“训练数据”的路径examples/mnist/mnist_train_lmdb和“测试数据”路径examples/mnist/mnist_test_lmdb:
name: "LeNet" //神经网络的名称是LeNet
layer { //定义一个网络层
name: "mnist" //网络层的名称是mnist
type: "Data" //网络层的类型是数据层
top: "data" //网络层的输出是data和label(有两个输出)
top: "label"
include { //定义该网络层只在训练阶段有效
phase: TRAIN
}
transform_param {
scale: 0.00390625 //归一化参数,输入的数据都是需要乘以该参数(1/256)
//由于图像数据上的像素值大小范围是0~255,这里乘以1/256
//相当于把输入归一化到0~1
}
data_param {
source: "examples/mnist/mnist_train_lmdb" //训练数据的路径
batch_size: 64 //每批次训练样本包含的样本数
backend: LMDB //数据格式(后缀)定义为LMDB,另一种数据格式是leveldb
}
}
layer { //定义一个网络层
name: "mnist" //网络层的名称是mnist
type: "Data" //网络层的类型是数据层
top: "data" //网络层的输出是data和label(有两个输出)
top: "label"
include { //定义该网络层只在测试阶段有效
phase: TEST
}
transform_param {
scale: 0.00390625 //归一化系数是1/256,数据都归一化到0~1
}
data_param {
source: "examples/mnist/mnist_test_lmdb" //测试数据路径
batch_size: 100 //每批次测试样本包含的样本数
backend: LMDB //数据格式(后缀)是LMDB
}
}
layer { //定义一个网络层
name: "conv1" //网络层的名称是conv1
type: "Convolution" //网络层的类型是卷积层
bottom: "data" //网络层的输入是data
top: "conv1" //网络层的输出是conv1
param {
lr_mult: 1 //weights的学习率跟全局基础学习率保持一致
}
param {
lr_mult: 2 //偏置的学习率是全局学习率的两倍
}
convolution_param { //卷积参数设置
num_output: 20 //输出是20个特征图
kernel_size: 5 //卷积核的尺寸是5*5
stride: 1 //卷积步长是1
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "pool1" //网络层的名称是pool1
type: "Pooling" //网络层的类型是池化层
bottom: "conv1" //网络层的输入是conv1
top: "pool1" //网络层的输出是pool1
pooling_param { //池化参数设置
pool: MAX //池化方式最大池化
kernel_size: 2 //池化核大小2*2
stride: 2 //池化步长2
}
}
layer { //定义一个网络层
name: "conv2" //网络层的名称是conv2
type: "Convolution" //网络层的类型是卷积层
bottom: "pool1" //网络层的输入是pool1
top: "conv2" //网络层的输出是conv2
param {
lr_mult: 1 //weights的学习率跟全局基础学习率保持一致
}
param {
lr_mult: 2 //偏置的学习率是全局学习率的两倍
}
convolution_param { //卷积参数设置
num_output: 50 //输出是50个特征图
kernel_size: 5 //卷积核的尺寸是5*5
stride: 1 //卷积步长是1
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "pool2" //网络层的名称是pool2
type: "Pooling" //网络层的类型是池化层
bottom: "conv2" //网络层的输入是conv2
top: "pool2" //网络层的输出是pool2
pooling_param { //池化参数设置
pool: MAX //池化方式最大池化
kernel_size: 2 //池化核大小2*2
stride: 2 //池化步长2
}
}
layer { //定义一个网络层
name: "ip1" //网络层的名称是ip1
type: "InnerProduct" //网络层的类型是全连接层
bottom: "pool2" //网络层的输入是pool2
top: "ip1" //网络层的输出是ip1
param {
lr_mult: 1 //指定weights权重初始化方式
}
param {
lr_mult: 2 //bias(偏置)的初始化全为0
}
inner_product_param { //全连接层参数设置
num_output: 500 //输出是一个500维的向量
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "relu1" //网络层的名称是relu1
type: "ReLU" //网络层的类型是激活函数层
bottom: "ip1" //网络层的输入是ip1
top: "ip1" //网络层的输出是ip1
}
layer { //定义一个网络层
name: "ip2" //网络层的名称是ip2
type: "InnerProduct" //网络层的类型是全连接层
bottom: "ip1" //网络层的输入是ip1
top: "ip2" //网络层的输出是ip2
param {
lr_mult: 1 //指定weights权重初始化方式
}
param {
lr_mult: 2 //bias(偏置)的初始化全为0
}
inner_product_param { //全连接层参数设置
num_output: 10 //输出是一个10维的向量,即0~9的数字
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "accuracy" //网络层的名称是accuracy
type: "Accuracy" //网络层的类型是准确率层
bottom: "ip2" //网络层的输入是ip2和label
bottom: "label"
top: "accuracy" //网络层的输出是accuracy
include { //定义该网络层只在测试阶段有效
phase: TEST
}
}
layer { //定义一个网络层
name: "loss" //网络层的名称是loss
type: "SoftmaxWithLoss" //网络层的损失函数采用Softmax计算
bottom: "ip2" //网络层的输入是ip2和label
bottom: "label"
top: "loss" //网络层的输出是loss
}
开始训练 Mnist
来到 Caffe 的根目录 D:\GitHub Repository\caffe 新建文件: run-train-mnist.txt :
build\x64\install\bin\caffe.exe train --solver=examples/mnist/lenet_solver.prototxt
pause
修改文件名为 run-train-mnist.bat ,双击运行,开始训练数据,结束后,在D:\GitHub Repository\caffe\examples\mnist 生成权值文件,可供测试数据使用。
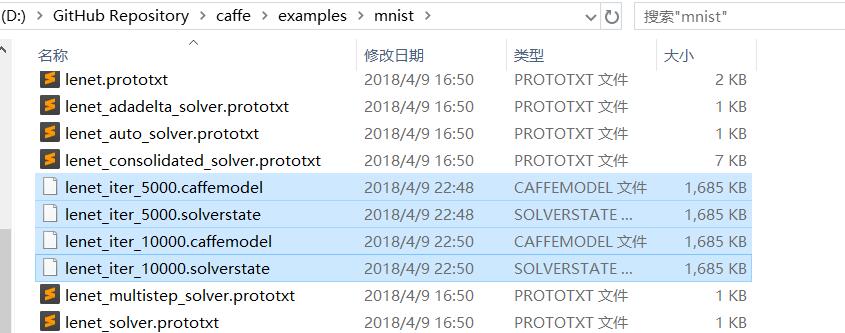
新建文件: run-test-mnist.txt :
build\x64\install\bin\caffe.exe test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_10000.caffemodel
pause
修改文件名 run-test-mnist.bat ,双击运行训练集。
顺带一提:
- 只要是用
caffe train -solver=xxxxxxx,那就是从头开始训练。 - 凡是遇到
caffe train -solver=xxxx -weights=xxxxxx.caffemodel,那就是用已有模型参数(权重偏置)去初始化网络,称为finetune。
结束!!
本作品采用知识共享署名-相同方式共享 4.0 国际许可协议进行许可。欢迎转载,并请注明来自:黄钢的博客 ,同时保持文章内容的完整和以上声明信息!